 RNN
RNN
吐故纳新,沙里淘金
之前我们看到的神经网络都是前馈型神经网络,网络的传播方向是单向的。这种网络不能很好地处理时间序列数据(简称时序数据),于是,循环神经网络(RNN)出现了。
# 1. 概率和语言模型
作为介绍 RNN 的准备,我们用概率描述自然语言相关的现象,最后介绍从概率视角研究语言的“语言模型”。
# 1.1 概率视角下的 word2vec
如果将上下文限定为左侧窗口,仅将左侧 2 个单词作为上下文的情况下,CBOW 模型输出的概率为
# 1.2 语言模型
语言模型给出了单词序列发生的概率,即在多大程度上是自然的单词序列。比如对“you say goodbye”这一单词序列给出高概率(比如 0.092),而对“you say good die”这一序列给出低概率(比如 0.00000032)。
语言模型可以应用于多种应用,典型的例子有机器翻译和语音识别,使用语言模型,可以按照“作为句子是否自然”这一基准对候选句子进行排序。语言模型也可以用于生成新的句子。因为语言模型可以使用概率来评价单词序列的自然程度,所以它可以根据这一概率分布造出(采样)单词。
m 个单词
使用后验概率可以拆解联合概率:
因此有:
注意这里的后验概率是以目标词左侧的全部单词为上下文(条件)时的概率:
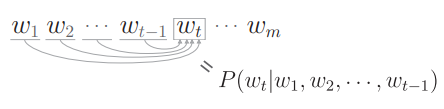
这里我们总结一下,我们的目标是求
# 1.3 将 CBOW 模型用作语言模型?
如果要把 word2vec 的 CBOW 模型(强行)用作语言模型,该怎么办呢?可以通过将上下文的大小限制在某个值来近似实现,比如限定为左侧 2 个单词:
马尔可夫性是指未来的状态仅依存于当前状态。此外,当某个事件的概率仅取决于其前面的 N 个事件时,称为“N 阶马尔可夫链”。这里展示的是下一个单词仅取决于前面 2 个单词的模型,因此可以称为“2 阶马尔可夫链”。
上下文大小虽说可以设定为任意长度,但必须是某个“固定”长度,这总会导致上下文更左侧的单词的信息会被忽略,比如:

- 这个问题要获得答案,比如把前面 18 个单词处的 Tom 记住,当 CBOW 上下文大小为 10 时,这个问题将无法被正确回答。
CBOW 模型还存在忽视了上下文中单词顺序的问题。当上下文大小为 2 时,CBOW 模型的中间层是那 2 个单词向量的和,,因此上下文的单词顺序会被忽视。比如 (you, say) 和 (say, you) 会被作为相同的内容进行处理。
CBOW 是 Continuous Bag-Of-Words 的简称。Bag-Of-Words 是“一袋子单词”的意思,这意味着袋子中单词的顺序被忽视了。
如果想要考虑上下文中单词顺序的模型,可以像下图那样拼接中间层,但这样会导致权重参数的数量将与上下文大小成比例地增加:
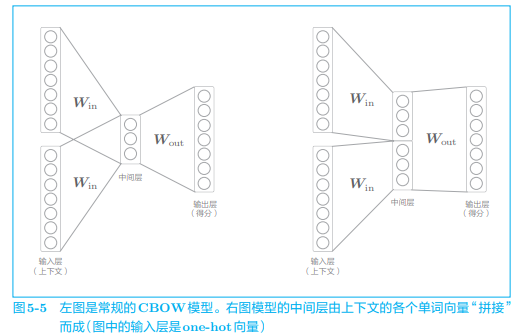
如何解决这些问题呢?这就轮到 RNN 出场了。RNN 具有一个机制,那就是无论上下文有多长,都能将上下文信息记住。因此,使用 RNN 可以处理任意长度的时序数据。
# 2. RNN
# 2.1 循环的神经网络
循环需要一个“环路”,随着数据的循环,信息不断被更新。RNN 的特征就在于拥有这样一个环路(或回路)。这个环路可以使数据不断循环。通过数据的循环,RNN 一边记住过去的数据,一边更新到最新的数据。
血液在我们体内循环。今天流动的血液是接着昨天的血液继续流动的。血液通过在体内循环,从过去一直被“更新” 到现在。
我们来看一下 RNN 层: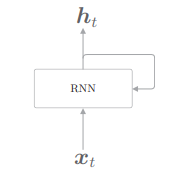
通过该环路,数据可以在层内循环。在上图中,时刻 t 的输入是
看一下 RNN 层中,可以发现输出有两个分叉,这意味着同一个东西被复制了。输出中的一个分叉将成为其自身的输入。
下面我们详细介绍一下这个循环结构。
# 2.2 展开循环
通过展开循环,可以将其转化为我们熟悉的神经网络:
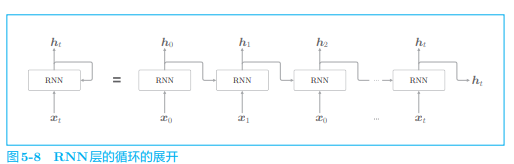
我们将其转化为了从左向右延伸的长神经网络,这样看上去数据就只向一个方向传播了。不过这里的多个 RNN 层都是同一个层。
时序数据按时间顺序排列。因此,我们用“时刻”这个词指代时序数据的索引(比如,时刻 t 的输入数据为
)。在 NLP 的情况下,既使用“第 t 个单词”“第 t 个 RNN 层”这样的表述,也使用“时刻 t 的单词”或者“时刻 t 的 RNN 层”这样的表述。
各个时刻的 RNN 层接收传给该层的输入和前一个 RNN 层的输出,然后据此计算当前时刻的输出:
符号说明
RNN 有两个权重:
- 将输入
- 将前一个 RNN 层的输出
从这个式子可以看出,现在输出的
RNN 的
存储“状态”,时间每前进一步,它就更新一次,因此称 为隐藏状态或隐藏状态向量。
# 2.3 Backpropagation Through Time
将循环展开后的 RNN 可以使用(常规的)误差反向传播法,因为这里的误差反向传播法是“按时间顺序展开的神经网络的误差反向传播法”,所以称为 Backpropagation Through Time(基于时间的反向传播),简称 BPTT。
但这还存在学习长时序数据的问题:因为随着时序数据的时间跨度的增大,BPTT 消耗的计算机资源也会成比例地增大。另外,反向传播的梯度也会变得不稳定。
# 2.4 Truncated BPTT
在处理长时序数据时,通常的做法是将网络连接截成适当的长度。具体来说,就是将时间轴方向上过长的网络在合适的位置进行截断,从而创建多个小型网络,然后对截出来的小型网络执行误差反向传播法,这个方法称为 Truncated BPTT(截断的 BPTT)。
在 Truncated BPTT 中,只是网络的反向传播的连接被截断,正向传播的连接依然被维持,反向传播则被截断为适当的长度,以被截出的网络为单位进行学习。
举个例子,在处理长度为 1000 的时序数据时,如果展开 RNN 层,它将成为在水平方向上排列有 1000 个层的网络,如果序列太长,就会出现计算量或者内存使用量方面的问题。此外,随着层变长,梯度逐渐变小,梯度将无法向前一层传递。我们来考虑在水平方向上以适当的长度截断反向传播的连接:
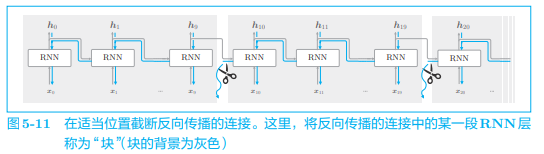
如上图,我们截断了反向传播的连接,以使学习可以以 10 个 RNN 层为单位进行,不需要再考虑块范围以外的数据了。
在 RNN 执行 Truncated BPTT 时,数据仍需要按顺序输入
我们考虑使用 Truncated BPTT 来学习 RNN。我们首先要做的是,将第 1 个块的输入数据
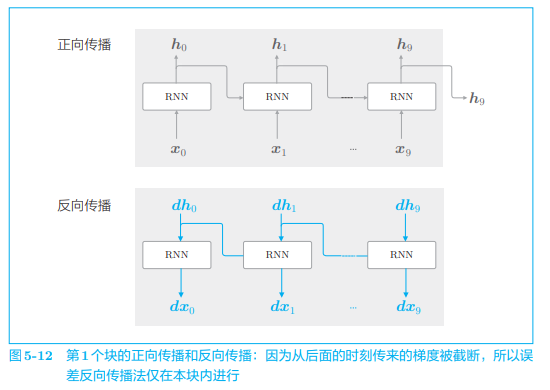
接着,对下一个块的输入数据
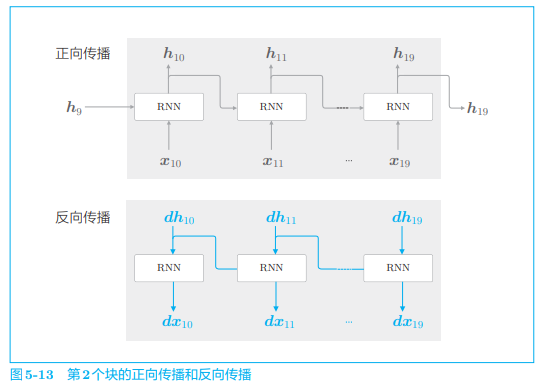
这里,和第 1 个块一样,先执行正向传播,再执行反向传播。这里的重点是,这个正向传播的计算需要前一个块最后的隐藏状态
用同样的方法,继续学习第 3 个块,此时要使用第 2 个块最后的隐藏状态
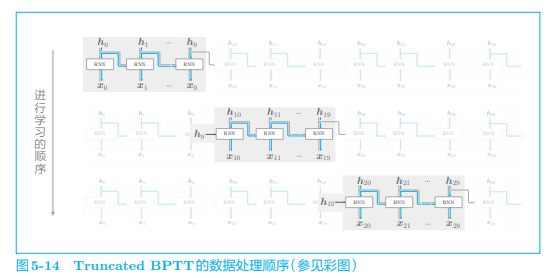
理解好这里的机制。
# 2.5 Truncated BPTT 的 mini-batch 学习
我们之前的探讨对应于批大小为 1 的情况,为了执行 mini-batch 学习,需要考虑批数据,让它也能按顺序输入数据,因此,在输入数据的开始位置,需要在各个批次中进行“偏移”。
为了说明“偏移”,我们用上一节的例子,对长度为 1000 的时序数据,以时间长度 10 为单位进行截断,此时如何将批大小设为 2 进行学习呢?在这种情况下,作为 RNN 层的输入数据, 第 1 笔样本数据从头开始按顺序输入,第 2 笔数据从第 500 个数据开始按顺序输入。也就是说,将开始位置平移 500:
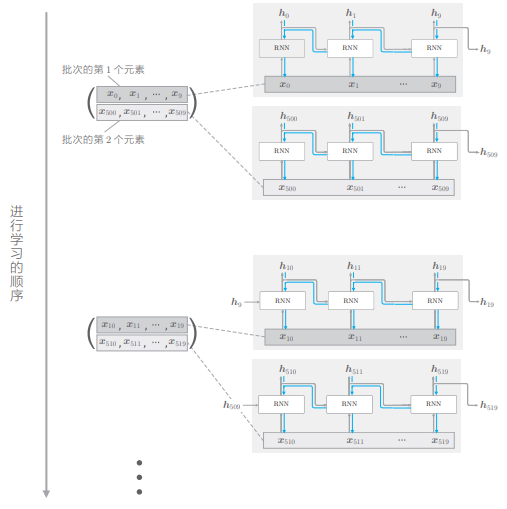
像这样,在进行 mini-batch 学习时,平移各批次输入数据的开始位置,按顺序输入。
关于数据的输入方法有几个需要注意的地方:
- 要按顺序输入数据
- 要平移各批次(各样本)输入数据的开始位置
之后可通过具体的代码来理解。
# 3. RNN 的实现
之前我们已经看到了 RNN 的全貌,实际上,我们要实现的是一个在水平方向上延伸的神经网络。考虑到基于 Truncated BPTT 的学习,只需要创建一个在水平方向上长度固定的网络序列即可,如下图:
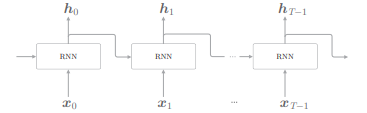
目标神经网络接收长度为 T 的时序数据,输出各个时刻的隐藏状态 T 个。考虑到模块化,将上图在水平方向上延伸的神经网络实现为“一个层”,如下图:
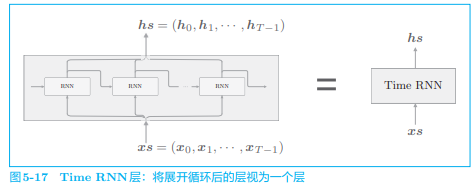
将垂直方向上的输入和输出分别捆绑在一起,就可以将水平排列的层视为一个层,这里,我们将进行 Time RNN 层中的单步处理的层称为“RNN 层”,将一次处理 T 步的层称为“Time RNN 层”。
我们规定将整体处理时序数据的层以单词“Time”开头命名,如 Time RNN 层、Time Affine 层等。
我们接下来的实现流程:先实现进行 RNN 单步处理的 RNN 类,然后利用它完成一次进行 T 步处理的 TimeRNN 类。
# 3.1 RNN 层的实现
RNN 层的正向传播数学式为:
这里我们将数据整理成 mini-batch 处理,因此
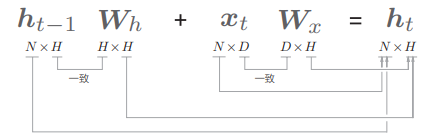
基于以上内容,现在我们给出 RNN 类的初始化方法和正向传播的 forward() 方法:
class RNN:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev):
Wx, Wh, b = self.params
t = np.dot(h_prev, Wh) + np.dot(x, Wx) + b
h_next = np.tanh(t)
self.cache = (x, h_prev, h_next)
return h_next
2
3
4
5
6
7
8
9
10
11
12
13
接下来,我们继续实现 RNN 的反向传播,根据其计算图画出它的反向传播:
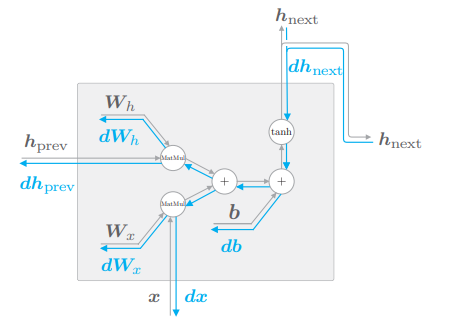
下面实现其 backward():
class RNN:
...
def backward(self, dh_next):
Wx, Wh, b = self.params
x, h_prev, h_next = self.cache
dt = dh_next * (1 - h_next ** 2)
db = np.sum(dt, axis=0)
dWh = np.dot(h_prev.T, dt)
dh_prev = np.dot(dt, Wh.T)
dWx = np.dot(x.T, dt)
dx = np.dot(dt, Wx.T)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
return dx, dh_prev
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
接下来,我们将实现 Time RNN 层。
# 3.2 Time RNN 层的实现
Time RNN 层是由 T 个 RNN 层连接起来的网络,这里,RNN 层的隐藏状态 h 要保存在成员变量中,在块之间进行隐藏状态的“继承”时会用到它:
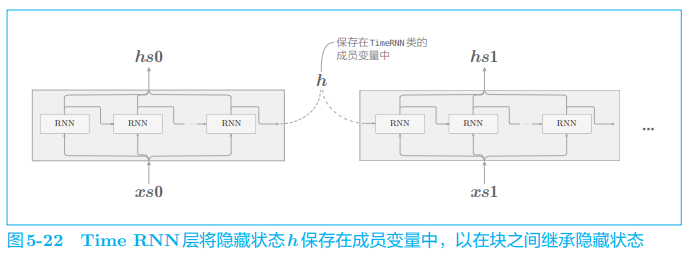
- 我们使用 Time RNN 层管理 RNN 层的隐藏状态,这样使用起来就不必考虑隐藏状态的“继承工作”了。另外,我们可以用
stateful这个参数来控制是否继承隐藏状态
首先实现 Time RNN 层的初始化方法和两个方法:
class TimeRNN:
def __init__(self, Wx, Wh, b, stateful=False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None
self.h, self.dh = None, None
self.stateful = stateful
def set_state(self, h):
self.h = h
def reset_state(self):
self.h = None
2
3
4
5
6
7
8
9
10
11
12
13
14
- 成员变量
h保存调用 forward() 方法时的最后一个 RNN 层的隐藏状态,dh保存调用 backward() 时传给前一个块的隐藏状态的梯度
在处理长时序数据时,需要维持 RNN 的隐藏状态,这一功能通常用“stateful”一词表示。在许多深度学习框架中,RNN 层都有 stateful参数,该参数用于指定是否保存上一时刻的隐藏状态。
当
stateful=True时表示有状态时,无论时序数据多长,Time RNN 层的正向传播都可以不中断地进行。
我们来看一下正向传播的实现:
class TimeRNN:
...
def forward(self, xs):
Wx, Wh, b = self.params
N, T, D = xs.shape
D, H = Wx.shape
self.layers = []
hs = np.empty((N, T, H), dtype='f')
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype='f')
for t in range(T):
layer = RNN(*self.params)
self.h = layer.forward(xs[:, t, :], self.h)
hs[:, t, :] = self.h
self.layers.append(layer)
return hs
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 正向传播的 forward(xs) 方法从下方获取输入 xs,xs 囊括了 T 个时序数 据。因此,如果批大小是 N,输入向量的维数是 D,则 xs 的形状为 (N,T, D)。
- 在首次调用时(self.h 为 None 时),RNN 层的隐藏状态 h 由所有元素均为 0 的矩阵初始化。另外,在成员变量 stateful 为 False 的情况下,h 将总是被重置为零矩阵。这才有了 line 12 的代码。
- 主要部分实现中,先将 hs 初始化为输出准备一个“容器”,之后 T 次循环中计算每次的隐藏状态并存放在 hs 的相应时刻的索引中。
在 stateful为 True 的情况下,在下 一次调用 forward() 方法时,存放隐藏状态的成员变量 h 将被继续使用;而在 stateful 为 False 的情况下,成员变量 h 将被重置为零向量。
接着实现反向传播:
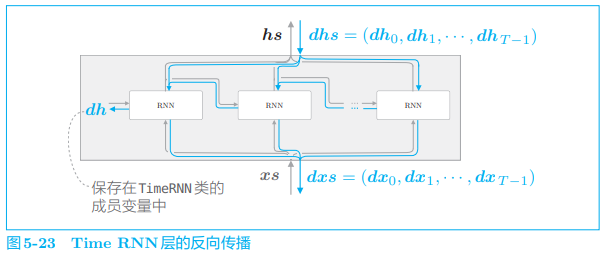
- 将从上游(输出侧的层)传来的梯度记为 dhs,将流向下游的梯度记为 dxs
- 由于使用了 Truncated BPTT,所以不需要流向这个块上一时刻的反向传播。不过,我们将流向上一时刻的隐藏状态的梯度存放在成员变量 dh 中,以便之后的 seq2seq 使用。
如果关注第 t 个 RNN 层,其反向传播如图:
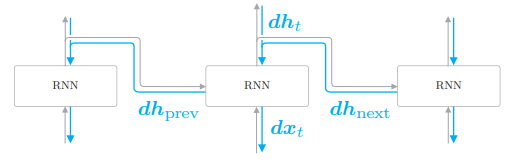
- 从上方传来的梯度
因此反向传播的实现:
class TimeRNN:
...
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D, H = Wx.shape
dxs = np.empty((N, T, D), dtype='f')
dh = 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh = layer.backward(dhs[:, t, :] + dh)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
在 Time RNN 层中有多个 RNN 层。另外,这些 RNN 层使用相同的权重。因此,Time RNN 层的(最终)权重梯度是各个 RNN 层的权重梯度之和
以上就是对 Time RNN 层的实现的说明。
# 4. 处理时序数据的层的实现
本节将创建几个可以处理时序数据的新层,我们称基于 RNN 的语言模型称为 RNNLM(RNN Language Model,RNN 语言模型)。
# 4.1 RNNLM 全貌图
下图为最简单的 RNNLM 的网络:
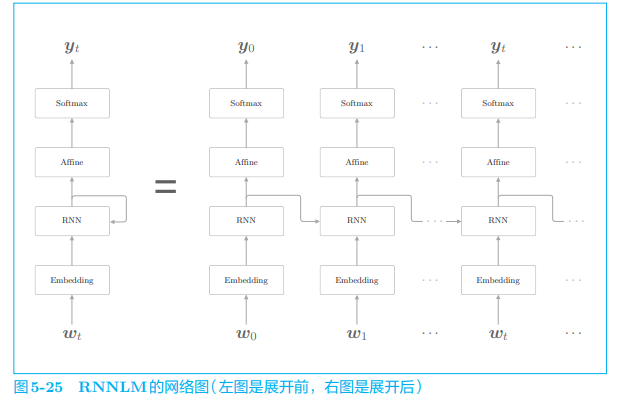
现在,我们仅考虑正向传播,向上图的神经网络传入具体的数据, 并观察输出结果,此处我们还是使用“you say goodbye and i say hello.”:
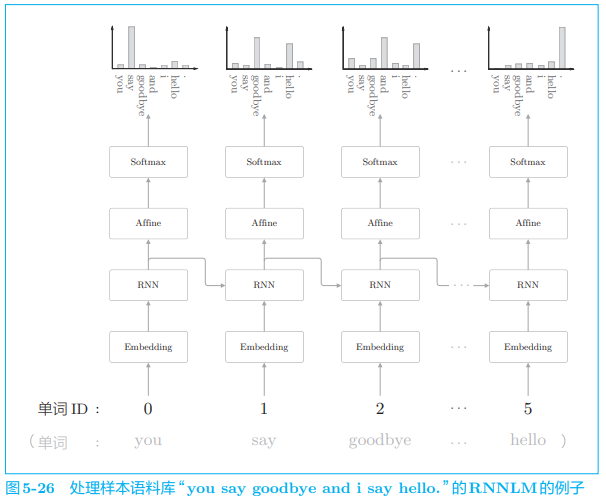
- 在第 1 个时刻,单词 ID 为 0 的 you 被输入
- 在第 2 个时刻需要注意的是 RNN 层“记忆”了“you say”这一上下文。更准确地说,RNN 将“you say”这一过去的信息保存为了简短的隐藏状态向量。RNN 层的工作是将这个信息传送到上方的 Affine 层和下一时刻的 RNN 层。
RNN 层通过从过去到现在继承并传递数据,使得编码和存储过去的信息成为可能,并以此为基础预测接下来会出现的单词。
# 4.2 Time 层的实现
我们使用 Time Embedding 层、Time Affine 层等来实现整体处理时序数据的层,这样我们的目标神经网络就可以像下图那样去实现:
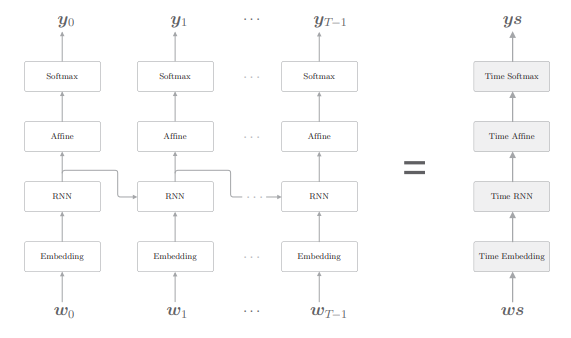
有了各 TimeXXX 层,就可以通过像组装乐高积木一样组装它们,来完成处理时序数据的网络。
TimeAffine 层的实现图示:
关于 Time Affine 层和 Time Embedding 层没有什么特别难的内容,我们就不再赘述了。
我们看一下时序版本的 Softmax。我们在 Softmax 中一并实现损失误差 Cross Entropy Error 层,这里我们按照下图的网络结构实现 Time Softmax with Loss 层:
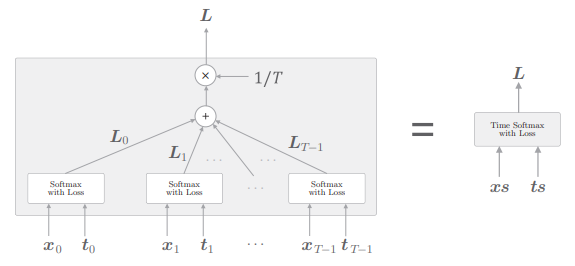
- 其中
T 个 Softmax with Loss 层各自算出损失,然后将它们加在一起取平均,将得到的值作为最终的损失:
另外,Softmax with Loss 层计算 mini-batch 的平均损失。具体而言,假设 mini-batch 有 N 笔数据,通过先求 N 笔数据的损失之和,再除以 N,可以得到单笔数据的平均损失。这里也一样,通过取时序数据的平均,可以求得单笔数据的平均损失作为最终的输出。
# 5. RNNLM 的学习和评价
实现 RNNLM 所需要的层都已经准备好了,现在我们来实现 RNNLM,并对其进行训练,然后再评价一下它的结果。
# 5.1 RNNLM 的实现
这里我们将 RNNLM 使用的网络实现为 SimpleRnnlm 类:
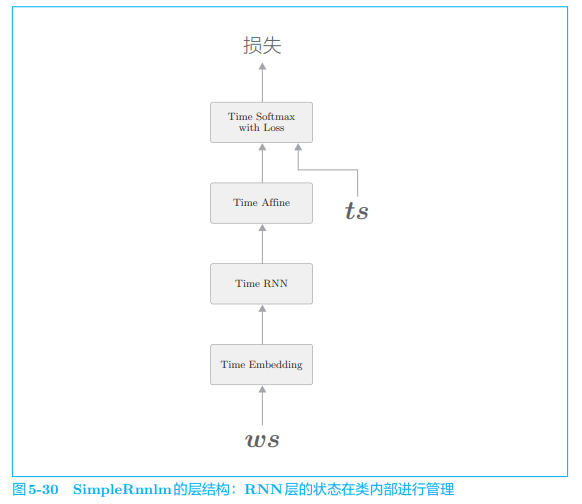
在实现中,RNN 层和 Affine 层使用了“Xavier 初始值”。
Xavier 初始值:在上一层的节点数是 n 的情况下,使用标准差为
的分布作为 Xavier 初始值。原始论文中提出的权重初始值还考虑了下一层的节点数。 之后我们都会使用 Xavier 初始值作为权重的初始值。另外,在语言模型的相关研究中,经常使用
0.01 * np.random.uniform(...)这样的经过缩放的均匀分布。
简单看一下 forward 实现:
def forward(self, xs, ts):
for layer in self.layers:
xs = layer.forward(xs)
loss = self.loss_layer.forward(xs, ts)
return loss
2
3
4
5
# 5.2 语言模型的评价
在实现用于学习的代码之前,我们先来讨论一下语言模型的评价方法。
语言模型基于给定的已经出现的单词(信息)输出将要出现的单词的概率分布。困惑度(perplexity)常被用作评价语言模型的预测性能的指标。
困惑度表示概率的倒数,比如向如下两个模型输入“you”:
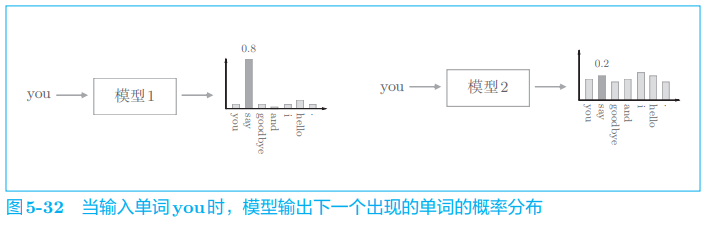
- 第一个模型预测正确单词 say 的概率为 0.8,取其倒数计算出困惑度为
- 第二个模型预测正确单词 say 的概率为 0.2,取其倒数计算出困惑度为
困惑度越小越好。那么,如何直观地解释值 1.25 和 5.0 呢?它们可以解释为“分叉度”。所谓分叉度,是指下一个可以选择的选项的数量(下一个可能出现的单词的候选个数)。
在刚才的例子中,好的预测模型的分叉度是 1.25,这意味着下一个要出现的单词的候选个数可以控制在 1 个左右。而在差的模型中,下一个单词的候选个数有 5 个。
基于困惑度可以评价模型的预测性能,好的模型可以高概率地预测出正确单词。
以上都是输入数据为 1 个时的困惑度。那么,在输入数据为多个的情况下,结果会怎样呢?我们可以根据下面的式子进行计算:
- 假设数据量为 N
- L 是神经网络的损失
这里的式子虽然看上去复杂,但是前面我们介绍的概念在这里也通用。也就是说,困惑度越小,分叉度越小,表明模型越好。
在信息论领域,困惑度也称为“平均分叉度”。这可以解释为,数据量为 1 时的分叉度是数据量为 N 时的分叉度的平均值
# 5.3 RNNLM 的学习代码
此部分具体代码可以参考鱼书的附带代码。
from common.trainer import RnnlmTrainer
...
model = SimpleRnnlm(vocab_size, wordvec_size, hidden_size)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)
trainer.fit(xs, ts, max_epoch, batch_size, time_size)
2
3
4
5
6
7
8
随着训练的进行,困惑度的演变如下图:
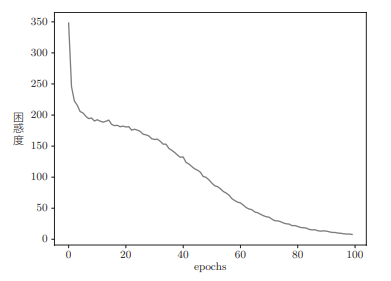
RnnlmTrainer 类的内部将执行如下的一系列操作:
- 按顺序生成 mini-batch
- 调用模型的正向传播和反向传播
- 使用优化器更新权重
- 评价困惑度
我们之后都会使用它来训练 RNNLM 网络。
小结
我们讨论了 RNN,它通过数据的循环,从过去继承数据并传递到现在和未来,如此,RNN 层的内部获得了记忆隐藏状态的能力。
理论上无论多么长的时序数据,都可以将它的重要信息记录在 RNN 的隐藏状态中。但是,在实际问题中,这样一来,许多情况下学习将无法顺利进行,下一章我们会指出 RNN 存在的问题,并研究替代 RNN 的 LSTM 层或 GRU 层。