 seq2seq
seq2seq
本章我们将利用 LSTM 实现几个有趣的应用。首先将使用语言模型进行文本生成,然后再介绍 seq2seq 的神经网络,将一个时序数据转换为另一个时序数据。
# 1. 使用语言模型生成文本
语言模型可用于各种各样的应用,其中具有代表性的例子有机器翻译、语音识别和文本生成。这里,我们将使用语言模型来生成文本。
# 1.1 使用 RNN 生成文本的步骤
上一章我们用 LSTM 层实现了语言模型,网络结构如下:
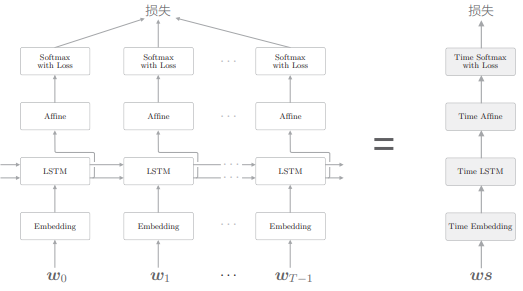
现在我们来说明一下语言模型生成文本的顺序。这里仍以“you say goobye and i say hello.”这一在语料库上学习好的语言模型为例,考虑将单词 i 赋给这个语言模型的情况:
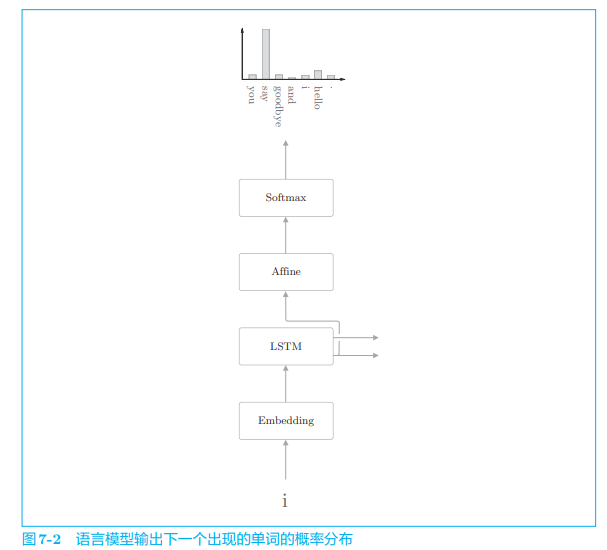
- 语言模型根据已经出现的单词输出下一个出现的单词的概率分布。
语言模型计算出下一个出现的单词的概率分布后,它如何生成下一个新单词呢?一种方法是选择概率最高的单词,这时结果能唯一确定;另一种方法是根据概率分布进行选择,这样概率高的单词容易被选到,这时被采样到的单词每次都不一样。
这里我们想让每次生成的文本有所变化,因此我们使用后一种方法来选择单词。下面是生成的过程:
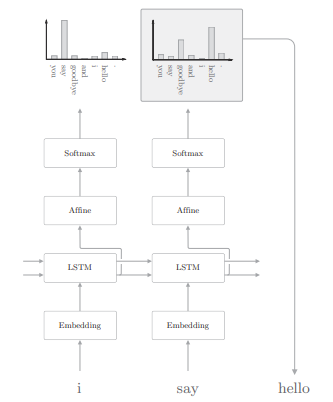
之后根据需要重复此过程即可,直到出现 <eos> 这一结尾记号,这样一来,我们就可以生成新的文本。
这里需要注意的是,像上面这样生成的新文本是训练数据中没有的新生成的文本。因为语言模型并不是背诵了训练数据,而是学习了训练数据中单词的排列模式。如果语言模型通过语料库正确学习了单词的出现模式,我们就可以期待该语言模型生成的文本对人类而言是自然的、有意义的。
# 1.2 文本生成的实现
下面我们进行文本生成的实现,我们基于上一章的 Rnnlm 类来创建继承自它的 RnnlmGen 类,然后向这个类添加生成文本的方法:
class RnnlmGen(Rnnlm):
def generate(self, start_id, skip_ids=None, sample_size=100):
word_ids = [start_id]
x = start_id
while len(word_ids) < sample_size:
x = np.array(x).reshape(1, 1)
score = self.predict(x)
p = softmax(score.flatten())
sampled = np.random.choice(len(p), size=1, p=p)
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_ids.append(int(x))
return word_ids
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这个类用 generate(start_id, skip_ids, sample_size) 生成本文,此处 start_id 是第一个单词 ID,sample_size 表示要采样的单词数量,skip_ids 是单词 ID 列表,它指定的单词将不被采样,这个参数用于排除 PTB 数据集中的 <unk> 、N 等被预处理过的单词。generate 方法首先通过 model.predict(x) 输出各个单词的得分,然后基于 p=softmax(score) 对得分进行正则化,这样就获得了我们想要的概率分布。
PTB 数据集对原始文本进行了预处理,稀有单词被
<unk>替换,数字被 N 替换。另外,我们用<eos>作为文本的分隔符。
现在,使用这个 RnnlmGen 类进行文本生成,这里先在完全没有学习的状态(即权重参数是随机初始值的状态)下生成文本。我们将第一个单词设为 you,可以得到如下的句子:

可见,输出的文本是一堆乱七八糟的单词,不过这可以理解,因此这里的模型权重使用的是随机初始值,所以输出了没有意义的文本。我们再利用上一章学习好的权重来进行文本生生成,为此使用 model.load_params(...) 读入学习好的参数,并生成文本:

虽然上面的结果中可以看到多处语法错误和意思不通的地方,不过也有几处读起来已经比较像句子了。这个实验生成的文本在某种程度上可以说是正确的,不过结果中仍有许多不自然的地方,改进空间很大。
# 1.3 更好的文本生成
之前我们改进了语音模型,实现了 BetterRnnlm 类们现在我们继承它并用于文本生成,结果如下:

可以看出,这个模型生成了比之前更自然的文本。
# 2. seq2seq 模型
文本数据、音频数据和视频数据都是时序数据,并存在许多需要将一种时序数据转换为另一种时序数据的任务,比如机器翻译、语音识别、聊天机器人、将源代码转为机器语言的编译器等。像这样,世界上存在许多输入输出均为时序数据的任务。现在我们会考察将时序数据转换为其他时序数据的模型,作为实现,我们将介绍使用两个 RNN 的 seq2seq 模型。
# 2.1 seq2seq 的原理
seq2seq 模型也称为 Encoder-Decoder 模型。这个模型有两个模块——Encoder(编码器)和 Decoder(解码器)。编码器对输入数据进行编码,解码器对被编码的数据进行解码。seq2seq 基于编码器和解码器将一个时序数据转换为另一个时序数据。
举一个例子来说明其机制,如下图,seq2seq 将日语翻译成了英语:
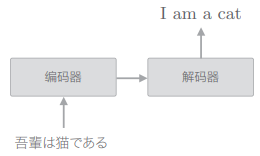
- 编码器编码的信息浓缩了翻译所必需的信息,解码器基于这个浓缩的信息生成目标文本
我们首先看一下编码器的细节:
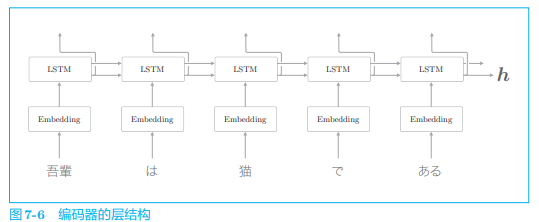
可以看出,编码器利用 RNN 将时序数据转换为隐藏状态
解码器是如何“处理”这个编码好的向量
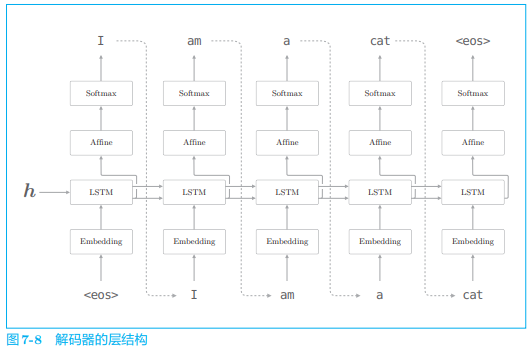
- 可以看出解码器的结构和文本生成的神经网络完全相同,不过存在一点点差异,就是 LSTM 层会接收向量
我们使用了
<eos>这一分隔符作为通知解码器开始生成文本的信号,另外,解码器采样到<eos>为止,作为结束信号。其他文献中也有使用<go>、<start>或_作为分隔符。
现在我们连接编码器和解码器,并给出它的层结构:
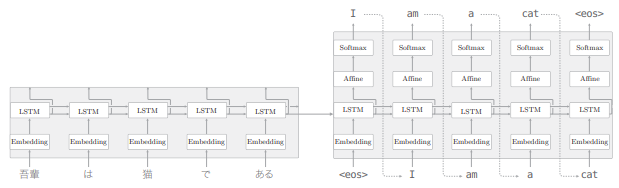
seq2seq 由两个 LSTM 层构成,即编码器的 LSTM 和解码器的 LSTM,此时 LSTM 层的隐藏状态是编码器和解码器的桥梁:
- 正向传播时,编码器的编码信息通过 LSTM 层的隐藏状态传递给解码器
- 反向传播时,解码器的梯度通过这个“桥梁”传递给编码器
# 2.2 时序数据转换的简单尝试
首先说明一下我们要处理的问题。这里我们将“加法”视为一个时序转换问题,效果如图:
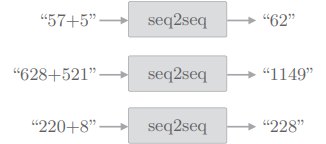
这种为了评价机器学习而创建的简单问题,称为 “toy problem”。
seq2seq 对加法逻辑一无所知,它从样本中出现的字符模式,真的可以学习到加法运算的规则吗?这正是本次实验的看头。在之前我们都把文本以单词为单位进行了分割,但并非必须这样做,这次我们将不以单词为单位,而是以字符为单位进行分割,比如“57 + 5”这样的输入会被处理为 ['5', '7', '+', '5'] 这样的列表。
还有一个问题,不同加法的字符数是不同的,比如“57 + 5”共有 4 个字符,而“628 + 521”共有 7 个字符。如此,在加法问题中,每个样本在时间方向上的大小不同。也就是说,加法问题处理的是可变长度的时序数据。
在使用批数据进行学习时,会一起处理多个样本。此时,(在我们的实现中)需要保证一个批次内各个样本的数据形状是一致的。
在基于 mini-batch 学习可变长度的时序数据时,最简单的方法是使用填充(padding)。填充就是用无效(无意义)数据填入原始数据,从而使数据长度对齐:
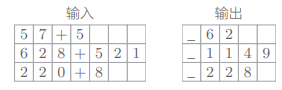
制作出如下的数据集并使用:
数据集原本应分成训练用、验证用和测试用 3 份。用训练数据进行学习,用验证数据进行调参,最后再用测试数据评价模型的能力。而简单起见,这里只分成训练数据和测试数据 2 份,用它们进行模型的训练和评价。
# 2.3 seq2seq 的实现
seq2seq 是组合了两个 RNN 的神经网络。这里我们首先将这两个 RNN 实现为 Encoder 类和 Decoder 类,然后将这两个类组合起来,来实现 seq2seq 类。
# 2.3.1 Encoder 类
Encoder 类接收字符串,将其转化为向量
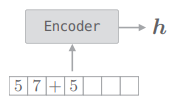
它的层结构展开后如下图:
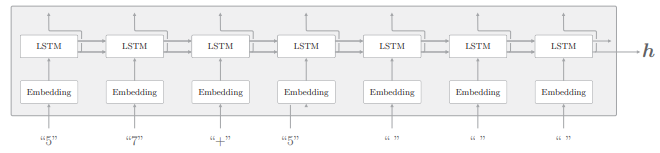
- Encoder 类由 Embedding 层和 LSTM 层组成,Embedding 层将字符(字符 ID)转化为字符向量,然后将字符向量输入 LSTM 层。
- LSTM 层向右(时间方向)输出隐藏状态和记忆单元,向上输出隐藏状 态。这里,因为上方不存在层,所以丢弃 LSTM 层向上的输出。在编码器处理完最后一个字符后,输出 LSTM 层的隐藏状态
编码器只将 LSTM 的隐藏状态传递给解码器。尽管也可以把 LSTM 的记忆单元传递给解码器,但我们通常不太会把 LSTM 的记忆单元传递给其他层。这是因为,LSTM 的记忆单元被设计为只给自身使用。
我们已经将时间方向上进行整体处理的层实现为了 Time LSTM 层和 Time Embedding 层,通过使用他们,我们的编码器将如下图所示:
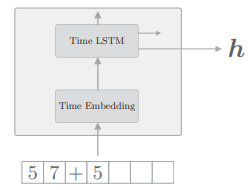
在初始化时,因为这次并不保持 Time LSTM 层的状态,所以设定 stateful=False。
之前的语言模型处理的是只有一个长时序数据的问题,那时我们设定 Time LSTM 层的参数 stateful=True,以在保持隐藏状态的同时,处理长时序数据。而这次是有多个短时序数据的问题。因此,针对每个问题重设 LSTM 的隐藏状态(为 0 向量)。
简单看一下其 forward 函数:
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
self.hs = hs
return hs[:, -1, :]
2
3
4
5
在编码器的反向传播中,LSTM 层的最后一个隐藏状态的梯度是 dh,这个 dh 是从解码器传来的梯度:
def backward(self, dh):
dhs = np.zeros_like(self.hs)
dhs[:, -1, :] = dh
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
2
3
4
5
6
# 2.3.2 Decoder 类
Decoder 类接收 Encoder 类输出的 h,输出目标字符串:
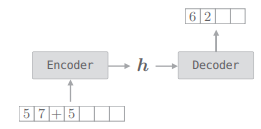
解码器可以由 RNN 实现,我们这里使用 LSTM:
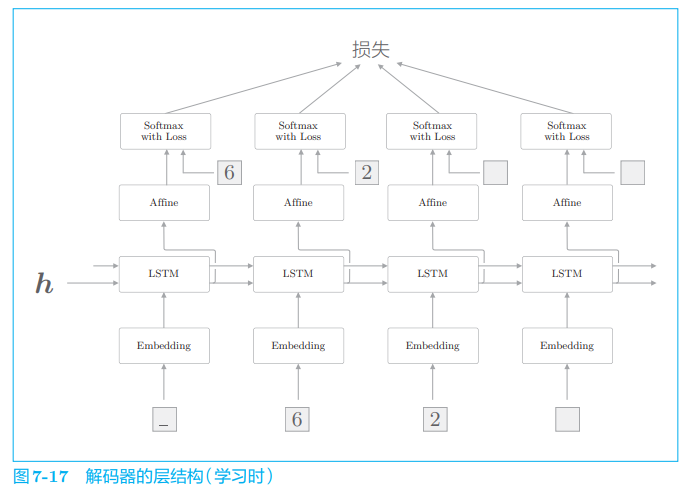
这里使用了监督数据 _62 进行学习,此时输入数据是 ['_', '6', '2',' '],对应的输出是 ['6', '2', ' ', ' ']。
在使用 RNN 进行文本生成时,学习时和生成时的数据输入方法不同:
- 在学习时,因为已经知道正确解,所以可以整体地输入时序方向上的数据。
- 在推理时(生成新字符串时),则只能输入第 1 个通知开始的分隔符(本次为“_”)。然后,基于输出采样 1 个字符,并将这个采样出来的字符作为下一个输入,如此重复该过程。
之前我们进行文本生成时,使用了概率分布来采样,因此生成的文本会随机变动。因为这次的问题是加法,所以我们想消除这种概率性的“波动”,生成“确定性的”答案。为此,这次我们仅选择得分最高的字符。下面是解码器生成字符串的过程:
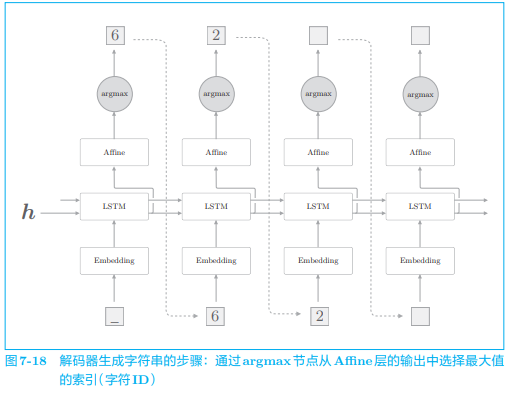
- argmax 是获取最大值的索引(本例中是字符 ID)的节点。
- 这次没有使用 Softmax 层,而是从 Affine 层输出的得分中选择了最大值的字符 ID
如上所述,在解码器中,在学习时和在生成时处理 Softmax 层的方式是不一样的。因此,Softmax with Loss 层交给此后实现的 Seq2seq 类处理。由此画出 Decoder 类的结构:
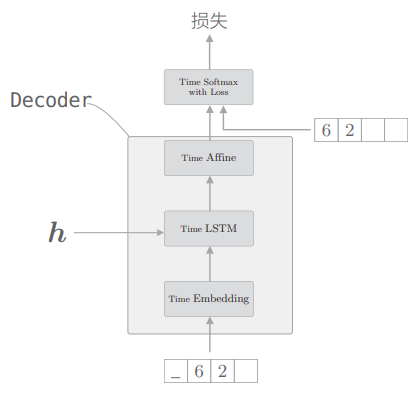
# 2.3.3 seq2seq 类
最后来看 Seq2seq 类的实现,这里需要做的只是将 Encoder 类和 Decoder 类连接在一起,然后使用 Time Softmax with Loss 层计算损失而已:
class Seq2seq(BaseModel):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = Decoder(V, D, H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
2
3
4
5
6
7
8
9
# 2.3.4 seq2seq 的评价
Seq2seq 的学习和基础神经网络的学习具有相同的流程。基础神经网络的学习流程如下:
- 从训练数据中选择一个 mini-batch
- 基于 mini-batch 计算梯度
- 使用梯度更新权重
这里使用 Trainer 类进行上述操作,另外,seq2seq 针对每个 epoch 求解测试数据(生成字符串),并计算正确率:
model = Seq2seq(vocab_size, wordvec_size, hidden_size)
optimizer = Adam()
trainer = Trainer(model, optimizer)
acc_list = []
for epoch in range(max_epoch):
trainer.fit(x_train, t_train, max_epoch=1,
batch_size=batch_size, max_grad=max_grad)
correct_num = 0
for i in range(len(x_test)):
question, correct = x_test[[i]], t_test[[i]]
verbose = i < 10
correct_num += eval_seq2seq(model, question, correct,
id_to_char, verbose, is_reverse)
acc = float(correct_num) / len(x_test)
acc_list.append(acc)
print('val acc %.3f%%' % (acc * 100))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 这里采 用正确率(正确回答了多少问题)作为评价指标
运行后的结果为:
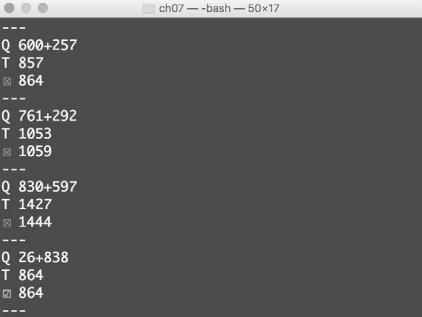
- 每个 epoch 显示一次结果,每个问题中, Q 代表问题,T 代表正确答案,第三行代表模型给出的答案。
随着学习的进行,上面的结果会发生什么样的变化:
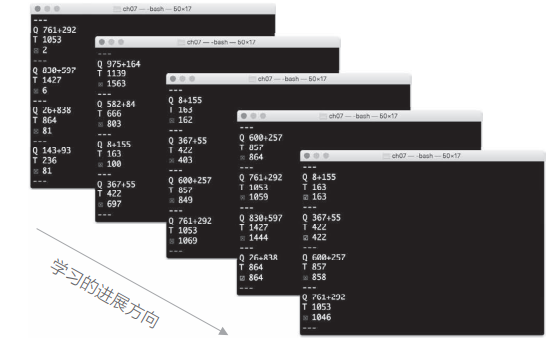
从结果中可知,seq2seq 最开始没能顺利回答问题。但是,随着学习不断进行,它在慢慢靠近正确答案,然后变得可以正确回答一些问题,直到最后的正确率约为 10%:
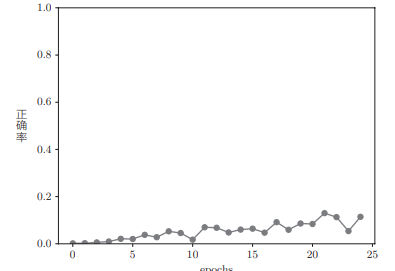
为了能更好地学习相同的问题,我们对 seq2seq 做一些改进。
# 3. seq2seq 的改进
我们对之前的 seq2seq 进行改进,以改进学习的进展。
# 3.1 反转输入数据(Reverse)
第一个改进方案是非常简单的技巧——反转输入数据的顺序:
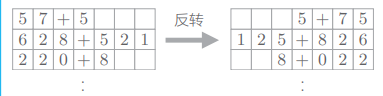
在许多情况下,使用这个技巧后,学习进展得更快,最终的精度也有提高。
为了反转输入数据,在读入数据集之后,我们追加下面的代码:
(x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt')
...
x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]
2
3
通过反转输入数据,正确率可以上升多少呢:
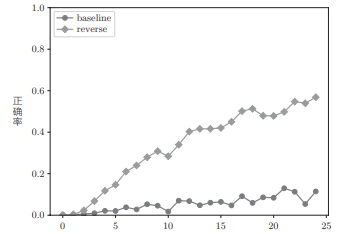
仅仅通过反转输入数据,学习的进展就得到了极大改善!虽然反转数据的效果因任务而异,但是通常都会有好的结果。
为什么反转数据后,学习进展变快,精度提高了呢?虽然理论上不是很清楚,但是直观上可以认为,反转数据后梯度的传播可以更平滑。比如,考虑将“吾輩 は 猫 で ある” 翻译成“I am a cat”这一问题,单词“吾輩”和单词“I”之间有转换关系,此时,从“吾輩”到“I”的路程必须经过“は”“猫”“で”“ある”这 4 个单词的 LSTM 层。因此,在反向传播时,梯度从“I”抵达“吾輩”,也要受到这个距离的影响。那么,如果反转输入语句,也就是变为“ある で 猫 は 吾輩”,结果会怎样呢?此时,“吾輩”和“I”彼此相邻,梯度可以直接传递。如此,因为通过反转,输入语句的开始部分和对应的转换后的单词之间的距离变近(这样的情况变多),所以梯度的传播变得更容易,学习效率也更高。不过,在反转输入数据后,单词之间的“平均”距离并不会发生改变。
# 3.2 偷窥(Peeky)
编码器将输入语句转换为固定长度的向量
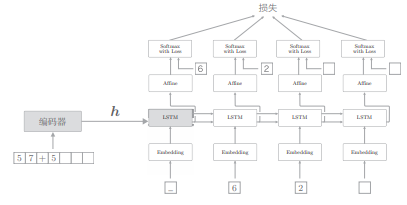
为了达成该目标,seq2seq 的第二个改进方案就应运而生了——将这个集中了重要信息的编码器的输出
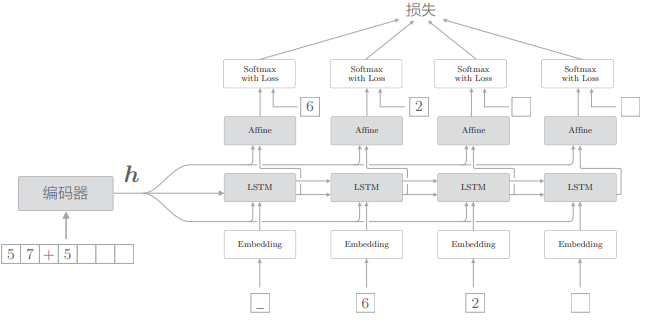
- 将编码器的输出
相较于之前,LSTM 层专用的重要信息
这里的改进是将编码好的信息分配给解码器的其他层,这可以解释为其他层也能“偷窥”到编码信息。因为“偷窥”的英语是 peek,所以将这个改进了的解码器称为 Peeky Decoder,其相应的 seq2seq 称为 Peeky seq2seq。
上图的结构中,有两个向量同时被输入到了 LSTM 层和 Affine 层,这实际上表示两个向量的拼接(concatenate)。如果使用 concat 节点拼接两个向量,则正确的计算图可以绘制成下图形式:
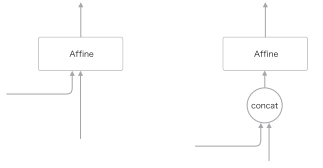
编码器与上一节没有变化。由于其实现并不难,我们省略了 PeekyDecoder 类的实现。
最后我们看一下实现 PeekySeq2seq,这和上一节的 Seq2seq 类基本相同,唯一的区别是 Decoder 层:
class PeekySeq2seq(Seq2seq):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = PeekyDecoder(V, D, H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
2
3
4
5
6
7
8
9
至此,准备工作就完成了,现在我们使用这个 PeekySeq2seq 类,再次挑战加法问题:
model = PeekySeq2seq(vocab_size, wordvec_size, hidden_size)
可以看到结果如图所示:
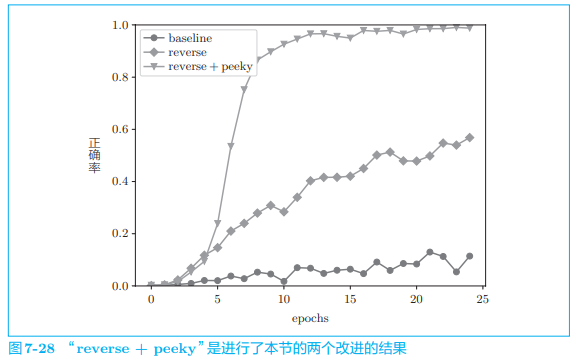
加上了 Peeky 的 seq2seq 的结果大幅变好。刚过 10 个 epoch 时,正确率已经超过 90%,最终的正确率接近 100%。
从上述实验结果可知,Reverse 和 Peeky 都有很好的效果。借助反转输入语句的 Reverse 和共享编码器信息的 Peeky,我们获得了令人满意的结果!
这里的实验有几个需要注意的地方。因为使用 Peeky 后,网络的权重参数会额外地增加,计算量也会增加,所以这里的实验结果必须考虑到相应地增加的“负担”。另外,seq2seq 的精度会随着超参数的调整而大幅变化。虽然这里的结果是可靠的,但是在实际问题中,它的效果可能不稳定。
# 4. seq2seq 的应用
seq2seq 将某个时序数据转换为另一个时序数据,这个转换时序数据的框架可以应用在各种各样的任务中:
- 机器翻译:将“一种语言的文本”转换为“另一种语言的文本”
- 自动摘要:将“一个长文本”转换为“短摘要”
- 问答系统:将“问题”转换为“答案”
- 邮件自动回复:将“接收到的邮件文本”转换为“回复文本”
像这样,seq2seq 可以用于处理成对的时序数据的问题。除了自然语言之外,也可以用于语音、视频等数据。
# 4.1 聊天机器人
聊天机器人是人和计算机使用文本进行对话的程序,因为对话是由“对方的发言”和“本方的发言”构成的,可以理解为是将“对方的发言”转换为“本方的发言”的问题。也就是说,如果有对话文本数据,seq2seq 就可以学习它:

这个机器人还无法泛化,但是,基于对话获取答案或者线索,这一点非常实用,应用范围很广。
# 4.2 算法学习
本章进行的 seq2seq 实验是加法这样的简单问题,但理论上它也能处理更加高级的问题:

可以直接将源代码输入 seq2seq,让 seq2seq 对源代码与目标答案一起进行学习。不过这类问题并不太好解决,通过改造 seq2seq 的结构,可以期待这样的问题能够被解决。
# 4.3 自动图像描述
自动图像描述将“图像”转换为“文本”:
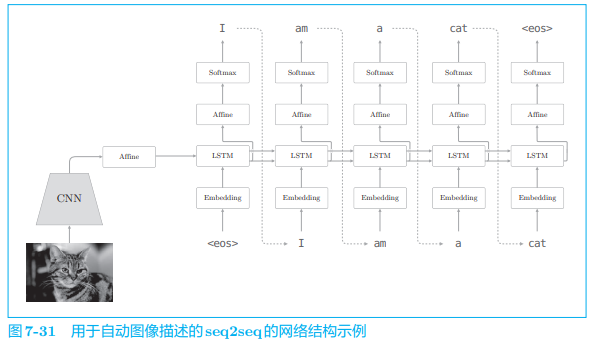
这时我们熟悉的网络结构,实际上,它和之前的网络的唯一区别在于,编码器从 LSTM 换成了 CNN,而解码器仍使用与之前相同的网络。仅通过这点改变(用 CNN 替代 LSTM),seq2seq 就可以处理图像了。
现在我们看几个基于 seq2seq 的自动图像描述的例子,这时由基于 TensorFlow 的 im2txt 生成的例子:

由图可知,这里得到了很不错的结果。之所以能够达到这样的效果,是因为存在大量的图像和说明文字等训练数据,再加上可以高效学习这些训练数据的 seq2seq 的应用,最终得到了如图所示的出色结果。
下一章我们将继续改进 seq2seq,届时深度学习中最重要的技巧之一 Attention 将会出现。