 Multiprocessors and locking
Multiprocessors and locking
这节课内容是 lock,比较偏理论介绍,也或许与其他课程中有关 lock 的内容有些重合,这节课更关注在 kernel 和 OS 中使用 lock。
# 1. 为什么要使用锁?
首先看一下为什么要使用锁?
一个应用程序可能会使用多个 CPU 核,这时可能出现并行的 system call,所以 system call 可能并行的运行在多个 CPU 核上,这时他们会并行访问 kernel 中共享的数据结构,所以,我们需要 lock 来协调对于共享数据的更新,以确保数据的一致性。
但实际情况有点问题,对共享数据使用 lock 会限制 system call 的性能,所以我们需要 trade-off:出于正确性,我们需要使用锁,但是考虑到性能,锁又是极不好的。
为什么程序一定要使用多个 CPU 来提升性能呢?在技术发展史上,CPU 的时钟频率很难再增加了,单线程性能达到了一个极限并且也没有再增加过了,而 CPU 中的晶体管数量在持续增加,导致现在不能通过单核来让代码运行地更快,唯一的选择就是利用多个 CPU 核。应用程序与内核的交互较为紧密,那么 OS 也需要高效地运行在多个 CPU 核上。这也就是我们对内核能够并行运行在多个 CPU 核上感兴趣的直接原因。
为什么要使用 lock 呢?是为了防止读写共享数据出现 race condition 等问题。比如,kernel 中将所有的空闲内存 page 放到了 freelist 数据结构中,当释放一个 page 时,kernel 会将该 page 加入到 freelist 中,看一下 xv6 的代码(kalloc.c):
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
在上面的代码中,修改 freelist 时使用了锁 kmem.lock 进行保护。这是如果你尝试把 lock 去掉,make qemu 后运行 usertests 你会发现可能会出现一些奇怪的报错。因为当两个 CPU 核上的两个线程同时调用 kfree 并交错执行更新 freelist 的代码时,就会出现不可预料的错误。
所以说,race condition 可能有不同的表现形式,并且有可能发生,有可能不发生。
# 2. 锁如何避免 race condition
解决 race condition 的常见方法就是使用 lock。
lock 是一个对象,与其他在 kernel 中的对象一样,有一个结构体叫做 lock,它包含了一些字段,这些字段维护了锁的状态。锁具有非常直观的 API:
- acquire:接收指向 lock 的指针作为参数。acquire 确保了在任何时间,只会有一个进程能够成功的获取锁。
- release:接收指向 lock 的指针作为参数,在同一时间尝试获取 lock 的其他进程需要等待,直到持有 lock 的进程对 lock 调用 release。
锁的 acquire 和 release 之间的代码叫做 critical section,这个 critical section 会以原子的方式来执行,也就是这些指令要么一起执行,要么一条也不会执行。lock 序列化了代码的执行,当两个处理器想要进入同一个 critical section 时,只有一个会成功进入,另一个需要等待 lock 释放后再进入,所以这里完全没有并行执行。
如果内核中只有一把大锁,我们称之为 big kernel lock,那基本上所有的 system call 都把被这把大锁保护起来而被序列化。当一个应用程序并行的调用多个 system call 时,这些 system call 都会串行地执行。而如果两个 system call 使用了两把不同的锁,那他们就能完全地并行运行。
# 3. 什么时候使用锁?
什么时候必须要加锁呢?这里有一个保守且简单的规则:如果两个进程访问同一个共享的数据结构,且其中一个需要更新,那就需要对这个共享的数据结构加锁。
同时,这个规则在某种程度又太过于严格了,两个进程并发更新一个数据结构时,有些场合不仅加锁也可以正常工作,不加锁的程序通常称为 lock-free program,不加锁的目的是为了获得更好的性能和并发度,不过 lock-free program 会更加复杂一些。在这节课的大部分时间我们还是考虑如何使用 lock 来控制共享数据。
但有时这个规则也太过宽松了。除了共享的数据,在有一些场合也需要锁。比如 printf,如果我们将一个字符串传递给它,XV6 会尝试原子性的将整个字符串输出,而不是与其他进程的 printf 交织输出。尽管这里没有使用共享的数据结构,但仍然使用了锁,因为我们也想要 printf 的输出也是序列化的。
所以说,这个规则并不完美,但它已经是一个足够好的指导准则了。
# 4. 锁的特性、死锁
通常 lock 有三种作用:
- lock 可以避免丢失更新。在 race condition 时,可能会出现某个进程对共享数据结构的更新被丢失。
- lock 可以打包多个操作,使它们具有原子性。critical section 的所有操作会都作为一个原子操作执行。
- lock 可以维护共享数据结构的不变性。共享数据结构如果不被任何进程修改的话会保持不变,但如果某个进程 acquire 了锁并做了更新操作,共享数据结构的不变性会被暂时破坏,但在 release 锁之后,数据的不变性又恢复了。
现在看一下 lock 可能带来的缺点。不正确地使用 lock 会带来一些问题,最明显的例子就是 deadlock。
一个 deadlock 的场景是:一个进程先 acquire 一个 lock,然后又在 critical section 中再次对这个 lock 进行 acquire,这样就卡住了。xv6 会探测这样的 deadlock:如果 xv6 看到了同一个进程多次 acquire 同一个锁,就会触发 panic。
还有一种场景:A 进程已经有了 a 锁,想去申请 b 锁,B 进程有了 b 锁,想去申请 a 锁,于是产生了 deadlock,这种场景也称为 deadly embrace。
这里的解决方案是:如果你有多个锁,你需要对锁进行排序,所有的操作都必须以相同的顺序获取锁。所以对于一个系统设计者,你需要确定对于所有的锁对象的全局的顺序。
不过在设计一个操作系统的时候,定义一个全局的锁的顺序会有些问题。如果一个模块 m1 中方法 g 调用了另一个模块 m2 中的方法 f,那么 m1 中的方法 g 需要知道 m2 的方法f使用了哪些锁。因为如果 m2 使用了一些锁,那么 m1 的方法 g 必须集合 f 和 g 中的锁,并形成一个全局的锁的排序。这意味着在 m2 中的锁必须对 m1 可见,这样 m1 才能以恰当的方法调用 m2。
但是这样又违背了代码抽象的原则。在完美的情况下,代码抽象要求 m1 完全不知道 m2 是如何实现的。但是不幸的是,具体实现中,m2 内部的锁需要泄露给 m1,这样 m1 才能完成全局锁排序。所以当你设计一些更大的系统时,锁使得代码的模块化更加的复杂了。
Question:有必要对所有的锁进行排序吗? Prof:在上面的例子中,这取决于 f 和 g 是否共用了一些锁。如果你看XV6的代码,你可以看到会有多种锁的排序,因为一些锁与其他的锁没有任何关系,它们永远也不会在同一个操作中被 acquire。如果两组锁不可能在同一个操作中被 acquire,那么这两组锁的排序是完全独立的。所以没有必要对所有的锁进行一个全局的排序,但是所有的函数需要对共同使用的一些锁进行一个排序。
# 5. 锁与性能
之前看了两类锁带来的挑战:
- deadlock
- 破坏了程序的模块化
现在来看一下第三个挑战:锁与性能之间的 trade-off。
基本上来说,如果你想获得更高的性能,你需要拆分数据结构和锁。
那怎么拆分呢?通常不会很简单,有的时候还有些困难。比如说,你是否应该为每个目录关联不同的锁?你是否应该为每个inode关联不同的锁?你是否应该为每个进程关联不同的锁?或者是否有更好的方式来拆分数据结构呢?如果你重新设计了加锁的规则,你需要确保不破坏内核一直尝试维护的数据不变性。
如果你拆分了锁,你可能需要重写代码。如果你为了获得更好的性能,重构了部分内核或者程序,将数据结构进行拆分并引入了更多的锁,这涉及到很多工作,你需要确保你能够继续维持数据的不变性,你需要重写代码。通常来说这里有很多的工作,并且并不容易。
所以这里就有矛盾点了:我们想要获得更好的性能,那么我们需要有更多的锁,但是这又引入了大量的工作。
通常来说,开发的流程是:
- 先以 coarse-grained lock(也就是大锁)开始
- 再对程序进行测试,看一下程序是否能使用多核
- 如果可以的话,工作就结束了,你对于锁的设计足够好了。如果不可以的话,那意味着锁存在竞争,多个进程会尝试获取同一个锁,因此它们将会序列化地执行,性能也上不去,之后你就需要重构程序了。
在这个流程中,测试的过程比较重要。有可能模块使用了coarse-grained lock,但是它并没有经常被并行的调用,那么其实就没有必要重构程序,因为重构程序设计到大量的工作,并且也会使得代码变得复杂。所以如果不是必要的话,还是不要进行重构。
# 6. xv6 中 UART 模块对 lock 的使用
下面看一下 xv6 的代码,通过代码理解一下锁是如何在 xv6 中工作的。
看一下 uart.c,从代码上看,URAT 就只有一个锁:
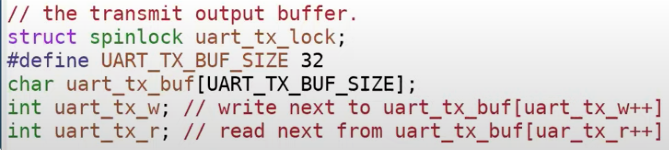
所以你可以认为 UART 模块就是 coarse-grained lock 的设计。这个 lock 保护了 UART 的传输缓存、写指针和读指针。我们之前知道了锁可以保护数据结构的特性不变,在这里:
- 读指针需要追赶写指针
- 从读指针到写指针之间的数据是需要被发送到显示端
- 从写指针到读指针之间的是空闲槽位
锁帮助我们维护了这些特性的不变。
我们接下来看一下 uart.c 中的 uartputc 函数:
void
uartputc(int c)
{
acquire(&uart_tx_lock);
if(panicked){
for(;;)
;
}
while(1){
if(((uart_tx_w + 1) % UART_TX_BUF_SIZE) == uart_tx_r){
// buffer is full.
// wait for uartstart() to open up space in the buffer.
sleep(&uart_tx_r, &uart_tx_lock);
} else {
uart_tx_buf[uart_tx_w] = c;
uart_tx_w = (uart_tx_w + 1) % UART_TX_BUF_SIZE;
uartstart();
release(&uart_tx_lock);
return;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
函数首先获得了锁,然后查看当前缓存是否还有空槽位,如果有的话将数据放置于空槽位中;写指针加 1;调用 uartstart;最后释放锁。由此,当多个进程想往缓存写数据的时候,就不会出现 race condition 的问题了。
接下来看一下 uartstart 函数:
// if the UART is idle, and a character is waiting
// in the transmit buffer, send it.
// caller must hold uart_tx_lock.
// called from both the top- and bottom-half.
void
uartstart()
{
while(1){
if(uart_tx_w == uart_tx_r){
// transmit buffer is empty.
return;
}
if((ReadReg(LSR) & LSR_TX_IDLE) == 0){
// the UART transmit holding register is full,
// so we cannot give it another byte.
// it will interrupt when it's ready for a new byte.
return;
}
int c = uart_tx_buf[uart_tx_r];
uart_tx_r = (uart_tx_r + 1) % UART_TX_BUF_SIZE;
// maybe uartputc() is waiting for space in the buffer.
wakeup(&uart_tx_r);
WriteReg(THR, c);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
如果uart_tx_w 不等于 uart_tx_r,那么缓存不为空,说明需要处理缓存中的一些字符。锁确保了我们可以在下一个字符写入到缓存之前,处理完缓存中的字符,这样缓存中的数据就不会被覆盖。
最后,锁确保了一个时间只有一个 CPU 上的进程可以写入 UART 的寄存器 THR。所以这里锁确保了硬件寄存器只有一个写入者。
当UART硬件完成传输,会产生一个中断。在前面的代码中我们知道了 uartstart 的调用者会获得锁以确保不会有多个进程同时向 THR 寄存器写数据。但是 UART 中断本身也可能与调用 printf 的进程并行执行。如果一个进程调用了 printf,它运行在 CPU 0 上,而 CPU 1 处理了 UART 中断,那么 CPU 1 也会调用 uartstart。因为我们想要确保对于 THR 寄存器只有一个写入者,同时也确保传输缓存的特性不变(注,这里指的是在 uartstart 中对与 uart_tx_r 指针的更新),我们需要在中断处理函数中也获取锁。
// handle a uart interrupt, raised because input has
// arrived, or the uart is ready for more output, or
// both. called from trap.c.
void
uartintr(void)
{
// read and process incoming characters.
while(1){
int c = uartgetc();
if(c == -1)
break;
consoleintr(c);
}
// send buffered characters.
acquire(&uart_tx_lock);
uartstart();
release(&uart_tx_lock);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
所以,在 XV6 中,驱动的 bottom 部分(注,也就是中断处理程序)和驱动的 up 部分(注,uartputc 函数)可以完全的并行运行,所以中断处理程序也需要获取锁。我们接下来会介绍,在实现锁的时候,为了确保这里能正常工作还是有点复杂的。
# 7. 自旋锁(spin lock)的实现
接下来看一下如何实现自旋锁。锁的特性就是只有一个进程可以获取锁,在任何时间点都不能有超过一个锁的持有者。接下来看一下锁是如何确保这里的特性的。
# 7.1 自旋锁的一个错误实现
这里先来看一个有问题的锁的实现,这样才能更好地理解这里的挑战是什么。
实现锁的主要难点在于锁的 acquire 接口,在 acquire 里面有一个死循环,循环中判断锁对象的 locked 字段是否为0,如果为 0 那表明当前锁没有持有者,当前对于 acquire 的调用可以获取锁。之后我们通过设置锁对象的 locked 字段为 1 来获取锁。最后返回。
bool acquire(struct lock * l) {
while (true) {
if (l->locked == 0) {
l->locked = 1;
return true;
}
}
}
2
3
4
5
6
7
8
如果锁的 locked 字段部位 0,那么当前对于 acquire 的调用就不能获取锁,程序会一直 spin,也就是说,程序在循环中不停地重复执行,直到锁地持有者调用了 release 并将锁对象的 locked 设置为 0。
但在实际情况中,这个实现会出现大问题,这会导致 race condition,导致可能两个进程同时读取到 locked 字段为 0,从而导致它们都认为自己完成了加锁。
# 7.2 test-and-set 指令
为了解决这里的问题并得到一个正确的锁的实现方式,其实有多种方法,但是最常见的方法是依赖于一个特殊的硬件指令。这个特殊的硬件指令会保证一次 test-and-set 操作的原子性。在 RISC-V 中,这个特殊指令就是 amoswap(atomic memory swap),这个指令接收 3 个参数:address、register r1、register r2。这条指令首先锁定住 address,将 address 中的数据保存在一个临时变量 tmp 里,之后将 r1 的数据写入到地址中,再将临时变量的值写入 r2 中,最后再对地址解锁。
上面介绍的这个特殊指令所做的一系列操作具备原子性,大多数处理器都有这样的硬件指令,因为这是一个实现锁的方便的方式。最终,我们将一个软件锁借助于硬件实现了原子性。不同处理器的具体实现可能会不一样,这依赖于内存系统是如何工作的。
# 7.3 实现自旋锁
接下来看一下如何使用这个特殊指令来实现自旋锁,也就是看一下 xv6 中 acquire 和 release 的实现。
首先看一下 spinlock.h:
// Mutual exclusion lock.
struct spinlock {
uint locked; // Is the lock held?
// For debugging:
char *name; // Name of lock.
struct cpu *cpu; // The cpu holding the lock.
};
2
3
4
5
6
7
8
如你所见,spinlock 的结构体定义十分简单,包含了 locked 字段用来表明当前是否上锁,其他两个字段用来输出调试信息。
接下来看一下 spinlock.c 中 acquire 函数的实现:
// Acquire the lock.
// Loops (spins) until the lock is acquired.
void
acquire(struct spinlock *lk)
{
push_off(); // disable interrupts to avoid deadlock.
if(holding(lk))
panic("acquire");
// On RISC-V, sync_lock_test_and_set turns into an atomic swap:
// a5 = 1
// s1 = &lk->locked
// amoswap.w.aq a5, a5, (s1)
while(__sync_lock_test_and_set(&lk->locked, 1) != 0)
;
// Tell the C compiler and the processor to not move loads or stores
// past this point, to ensure that the critical section's memory
// references happen strictly after the lock is acquired.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Record info about lock acquisition for holding() and debugging.
lk->cpu = mycpu();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
这个函数有一个 while 循环,也就是刚刚提到的 test-and-set 循环,实际上 C 标准库已经定义了这个原子操作,也就是标准库函数 __sync_lock_test_and_set,它里面的具体行为与我刚刚描述的是一样的,因为大部分处理都有 test-and-set 硬件指令,所以这个函数的实现比较直观。我们可以通过查看 kernel.asm 来了解 RISC-V 是如何具体实现的,下图就是 atomic swap 操作:

这里比较复杂,总的来说有两种情况,一种情况是我们跳出了循环,一种情况是我们继续执行循环。C 代码就要简单的:如果锁没有被持有,那么锁对象的locked字段会是0,如果locked字段等于0,我们调用test-and-set将1写入locked字段,并且返回locked字段之前的数值0。如果返回0,那么意味着没有人持有锁,循环结束。如果locked字段之前是1,那么这里的流程是,先将之前的1读出,然后写入一个新的1,但是这不会改变任何数据,因为locked之前已经是1了。之后__sync_lock_test_and_set会返回1,表明锁之前已经被人持有了,这样的话,判断语句不成立,程序会持续循环(spin),直到锁的locked字段被设置回0。
接下来我们看一下 release 的实现,首先看一下 kernel.asm 中的指令:
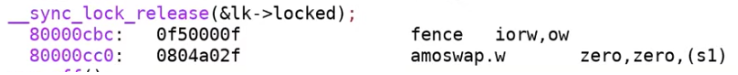
可以看出 release 也使用了 atomic swap 操作,将 0 写入到了 s1。下面是对应的 C 代码,它基本确保了将 lk->locked 中写入 0 是一个原子操作:
// Release the lock.
void
release(struct spinlock *lk)
{
if(!holding(lk))
panic("release");
lk->cpu = 0;
// Tell the C compiler and the CPU to not move loads or stores
// past this point, to ensure that all the stores in the critical
// section are visible to other CPUs before the lock is released,
// and that loads in the critical section occur strictly before
// the lock is released.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Release the lock, equivalent to lk->locked = 0.
// This code doesn't use a C assignment, since the C standard
// implies that an assignment might be implemented with
// multiple store instructions.
// On RISC-V, sync_lock_release turns into an atomic swap:
// s1 = &lk->locked
// amoswap.w zero, zero, (s1)
__sync_lock_release(&lk->locked);
pop_off();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 7.4 一些细节的讨论
这里有关 spin lock 的实现,有 3 个细节想介绍一下。
第一个细节是,为什么 release 函数不直接使用一个 store 指令来将 locked 字段写入 0?
原因在于 store 指令并不是一个原子指令,其内部实现可能会涉及 CPU 缓存、多个微指令等等,这样的话可能就会得到错误的结果。为了避免硬件实现细节的问题,我们还是直接使用 RISC-V 直接提供的原子性指令比较好。
amoswap 并不是唯一的原子指令,RISC-V 手册列出了所有的原子指令。

第二个细节是,acquire 函数最开始会先关闭中断。原因在于,uartputc 函数会 acquire 锁,而 UART 本质上就是传输字符,在它传输完后会产生一个中断来运行 uartintr 函数,而 uartintr 函数会获取同一把锁,但这把锁正在被 uartputc 所持有,而如果这里只有一个 CPU 的话,那就会产生死锁,即同一个 CPU 程序在重复申请同一把锁,这会触发 panic。
所以,spinlock 需要处理两类并发:一类是不同 CPU 之间的并发,一类是相同 CPU 上中断程序和普通程序之间的并发。针对后一种情况,我们需要在 acquire 中关闭中断,中断会在 release 结束位置再次被打开,因为这个位置才能再次安全地接收中断。
第三个细节就是 memory ordering。假设我们先通过将 locked 字段设置为 1 来获取锁,之后又对 x 加 1,最后再将 locked 字段设置为 0 来释放锁,那么下面就是在 CPU 上执行的指令流:
locked <- 1
x <- x + 1
locked <- 0
2
3
但是编译器或者处理器可能会重排指令以获得更好的性能。对于上面的串行指令流,如果将 x <- x + 1 移到 locked <- 0 后面并不会改变串行执行下指令流的正确性,因为 x 和 locked 是没有关联的,但是这会导致在并发场景下出现灾难。所以,指令重排在并发场景下是错误的。
为了禁止指令重排,或者说为了告诉编译器和硬件不要这样做,我们需要 memory fence 或者 synchronize 指令,来确定指令的移动范围。对于 synchronize 指令,任何在它之前的 load/store 指令,都不能移动到它之后。锁的 acquire 和 release 函数都包含了 synchronize 指令。
// Release the lock.
void
release(struct spinlock *lk)
{
if(!holding(lk))
panic("release");
lk->cpu = 0;
// Tell the C compiler and the CPU to not move loads or stores
// past this point, to ensure that all the stores in the critical
// section are visible to other CPUs before the lock is released,
// and that loads in the critical section occur strictly before
// the lock is released.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Release the lock, equivalent to lk->locked = 0.
// This code doesn't use a C assignment, since the C standard
// implies that an assignment might be implemented with
// multiple store instructions.
// On RISC-V, sync_lock_release turns into an atomic swap:
// s1 = &lk->locked
// amoswap.w zero, zero, (s1)
__sync_lock_release(&lk->locked);
pop_off();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
这样前面的例子中,x<-x+1 就不会被移到特定的 memory synchronization 点之外。我们也就不会有 memory ordering 带来的问题。这就是为什么在 acquire 和 release 中都有 __sync_synchronize 函数的调用。
# 8. 总结
总结一下这节课的内容。
首先,锁确保了正确性,却又降低了性能。
其次,锁会增加编写程序的复杂性。如果你在程序中使用了并发,那么一般都需要使用锁。如果你想避免锁带来的复杂性,可以遵循以下原则:不到万不得已不要共享数据。如果你不在多个进程之间共享数据,那么 race condition 就不可能发生,那么你也就不需要使用锁,程序也不会因此变得复杂。但是通常来说如果你有一些共享的数据结构,那么你就需要锁,你可以从 coarse-grained lock 开始,然后基于测试结果,向 fine-grained lock 演进。
最后,使用 race detector 来找到 race condition,如果你将锁的 acquire 和 release 放置于错误的位置,那么就算使用了锁还是会有 race。