 OS Organization and System Calls
OS Organization and System Calls
# 1. 回顾
这节课内容是操作系统的组织结构,主要讨论四个话题:
- Isolation:隔离性是设计操作系统组织结构的驱动力。
- Kernel/User mode:这两种模式用来隔离操作系统内核和用户应用程序。
- System call:系统调用是你的应用程序能够转换到内核执行的基本方法,这样你的用户态应用程序才能使用内核服务。
- 如何在 xv6 中实现。
先回顾一下上节课内容,从上节课你应该对 OS 的结构有一个大致的认知:
- 首先,会有类似于 shell、echo、find 或者任何你实现的工具程序,这些程序运行在操作系统之上。
- 而操作系统又抽象了一些硬件资源,例如磁盘、CPU。
- 通常来说操作系统和应用程序之前的接口被称为系统调用接口(System call interface),我们这门课程看到的接口都是Unix风格的接口。基于这些Unix接口,你们在lab1中,完成了不同的应用程序。
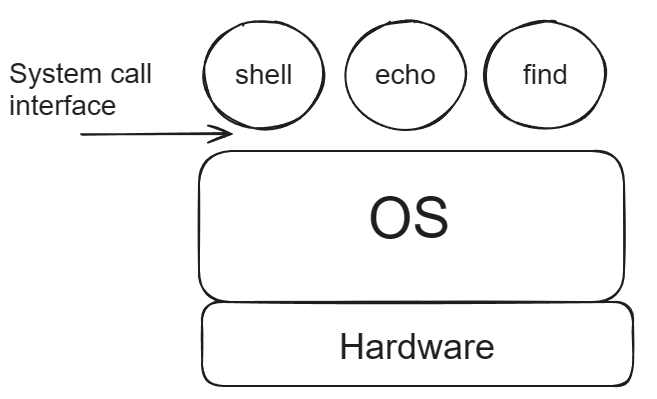
这学期我们主要花时间来理解如何实现操作系统接口(也就是系统调用接口)。
# 2. 操作系统的隔离性(Isolation)
这里先简单介绍一下隔离性(Isolation),以及为什么它很重要。
Isolation 的核心思想是:用户空间可以有多个应用程序,如 shell、echo 等,如果你通过 shell 来运行 echo、find 等程序代码时,假如代码出现了问题,shell 不应该影响到其他的应用程序(比如杀死了另一个进程)。所以,你需要在不同的应用程序之间有强隔离性。
类似的,由于操作系统是为所有其上层应用程序服务的,当你的程序出现问题时(传递了错误的参数进行系统调用),你会希望 OS 不会因此而崩溃,也就是你希望 OS 能较好地处理异常情况。所以,你需要在应用程序和操作系统之间也有强隔离性。
头脑风暴一下,如果没有操作系统会怎么样?如果没有操作系统,应用程序会直接与硬件交互。比如,应用程序可以直接看到CPU的多个核,看到磁盘,内存。所以现在应用程序和硬件资源之间没有一个额外的抽象层。假如一个用户程序使用上一个 CPU 来运行,而不幸这个程序有一个无限循环的 bug,这导致这个程序永远也不会释放 CPU,进而导致其他应用程序也无法运行。在这种场景下,我们无法得到真正的 CPU 多进程分时复用。而有了操作系统,不论应用程序在执行什么操作,multiplexing 特性都会迫使应用程序时不时的释放 CPU,这样其他的应用程序才能运行。
另外,如果应用程序直接运行在硬件资源上,那每个数据都是直接保存在物理内存中,整个物理内存一部分被 shell 使用,一部分被 echo 使用,这些程序的内存之间没有边界,程序很容易由于溢出而覆盖了其他人的数据,从而导致难以预测的 bug。而有了操作系统,我们就可以让不同应用程序之间的内存是隔离的了。
使用操作系统的一个主要原因就是为了实现 multiplexing 和内存隔离。
Unix 接口通过抽象硬件资源,使得提供强隔离成为可能:
- 进程抽象了 CPU。我们通过系统调用
fork创建了进程,进程本身不是 CPU,但它们对应了 CPU,使得你可以在 CPU 上运行计算任务。所以,应用程序不能直接与 CPU 交互,只能与进程交互,OS kernel 完成不同进程在 CPU 上的切换。 - exec 抽象了内存。我们在执行 exec 系统调用时,会传入一个文件名,这个文件名就对应了一个应用程序的内存镜像,内存镜像包括了程序的指令、全局数据等。应用程序可以逐渐扩展自己的内存,但是应用程序并没有直接访问物理内存的权限。OS kernel 会提供内存隔离并控制内存,操作系统会在应用程序和内存之间提供一个中间层。
- 文件抽象了磁盘。应用程序不会直接读写挂在计算机上的磁盘本身,在 Unix 中,与存储系统交互的唯一方式就是通过 files。File 提供了磁盘抽象,OS kernel 决定如何将文件与磁盘中的块对应。
以上就是从隔离性的角度来看 Unix 系统调用接口的设计,这种接口实现使得 OS 本身可以在多个应用程序之间复用计算机硬件资源,同时提供了强隔离性。
# 3. 操作系统的防御性(Defensive)
内核开发时,防御性是你需要熟悉的重要思想。操作系统需要确保所有的组件都能工作,所以它需要做好准备抵御来自应用程序的攻击。如果说应用程序无意或者恶意的向系统调用传入一些错误的参数就会导致操作系统崩溃,从而导致操作系统无法继续为其他所有程序提供服务。所以,操作系统需要能够应对恶意的应用程序。
恶意的应用程序会想要打破 OS 对它的隔离,进而控制内核,由此就可以控制所有的硬件资源。所以 OS kernel 需要具备防御性来避免这种事情的发生。
为了满足这种要求,应用程序和 OS kernel 之间需要有一堵后墙,并且 OS 可以在这堵墙上执行任何它想执行的策略。通常来说,需要通过硬件来实现这里的强隔离性,这节课会简单介绍一些硬件隔离的措施:一个是 user/kernel mode,一个是 page table 或者叫 virtual memory。
所以,所有处理器,如果需要运行能够支持多个应用程序的操作系统,那就需要同时支持 user/kernel mode 和 virtual memory。具体实现会有细微差别,但基本上所有处理都能支持这些。
# 4. 硬件对于强隔离的支持
硬件上对强隔离的支持主要包括:user/kernel mode 和 virtual memory。
# 4.1 user/kernel mode
这里尽可能从全局的视角来介绍,略过具体的细节。
处理器有两种操作模式:user mode 和 kernel mode。
在运行 kernel mode 时,CPU 可以运行特定权限的指令(privileged instructions)
当运行 user mode 时,CPU 只能运行普通权限的指令(unprivileged instructions)。
普通权限的指令都是一些我们熟悉的指令,比如 ADD、SUB、跳转指令 JRC 等等,所有应用程序都允许执行这些普通权限指令。
特殊权限指令主要是一些直接操纵硬件的指令和设置保护的指令,例如设置 page table 寄存器、关闭时钟中断。在处理器上有各种各样的状态,操作系统会使用这些状态,但是只能通过特殊权限指令来变更这些状态。
当应用程序尝试执行 privileged instructions 时,处理器会拒绝执行,这时 OS kernel 可能会拿过控制权并杀掉这个进程。
RISC-V 的架构文档中介绍了所有的特殊权限指令,之后你可能就需要与他们进行打交道。
处理器中会存在一个 bit 的 flag 来标识当前的运行模式,从而区分 user mode 和 kernel mode。实际上,RISC-V 还有第三种模式称为 machine mode,大部分场景下我们会忽略它,这里也不再介绍。
# 4.2 virtual memory
基本上所有 CPU 都支持 virtual memory,下节课会深入讨论它,这里先做一个简单介绍。
处理器包括了 page table,page table 将虚拟内存地址与物理内存地址做了对应。每个进程有自己独立的 page table,这个进程也只能访问出现在自己 page table 中的物理内存。
page table 定义了对于内存的视图,而每一个用户进程都有自己对于内存的独立视图,每个进程都认为自己的内存地址从 0 开始。这给了我们非常强的内存隔离性。
# 5. User/Kernel mode 切换
user/kernel mode 是分隔用户空间和内核空间的边界,用户空间运行的程序运行在 user mode,内核空间的程序运行在 kernel mode。操作系统位于内核空间。

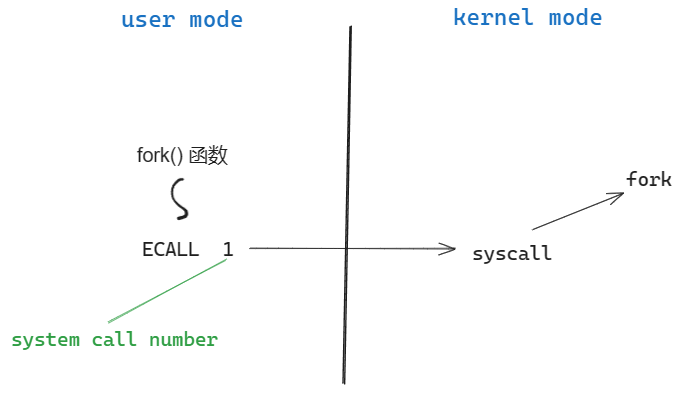
应用程序在运行时,需要有一种方式来将控制权转移给 OS kernel 来获得 kernel 提供的服务。在 RISC-V 中,有一个专门的指令实现了这个功能:ECALL。ECALL 接收一个数字(system call number)并将控制权交给内核来执行系统调用。
ECALL 会跳转到内核中一个特定位置,并从这个接入点进入内核。所以,应用程序如果想要进行系统调用,都要通过 ECALL 指令进入内核。
需要澄清的是,用户空间和内核空间的界限是一个硬性的界限,用户不能直接调用 system call fork,想要执行系统调用的唯一方法就是通过 ECALL 指令 + system call number。
# 6. 宏内核 vs 微内核
当应用程序通过系统调用转移到内核后,内核会负责实现具体的功能并检查参数防止问题。所以内核有时候也被称为可信任的计算空间(Trusted Computing Base,TCB)。
如果要被称为 TCB,内核首先要是正确且没有 bug 的,一旦存在 bug 就会被攻击者利用。内核也必须将用户程序当作是恶意的,小心检查各种情况防止出现小的疏漏。
一个有趣的问题是,什么程序应该运行在 kernel mode?
首先我们会有 user / kernel 的边界。其中一个选项是让整个 OS 代码都运行在 kernel mode,比如 xv6 和大多数 Unix 的所有 OS 服务都运行在 kernel mode,这种形式被称为 Monolithic Kernel Design(宏内核)。
- 如果考虑 bug 的话,这种方式不太好,因为宏内核的任何一个 OS bug 都可能称为漏洞并被利用,尤其是当前庞大的 OS 代码不可避免地存在大量 bug。
- 如果考虑性能的话,OS 涉及到多个子模块,比如 FS、virtual memory 等,宏内核的优势是将这些子模块紧密集成在一起,这种集成提供了很好的性能。
另一种设计的关注点是减少内核的代码,他被称为 Micro Kernel Design(微内核)。这种设计下只有少量代码运行在 kernel mode 下,内核也只有很少的几个模块,比如内核可能会有一些 IPC 实现、非常少的虚拟内存支持、非常少的分时复用 CPU 的支持。微内核将大部分的 OS 都运行在内核之外,比如文件系统可能就是个常规的用户空间程序。
- 由于内核代码数量少,也意味着有更少的 bug。
- 但为了多个模块交互,会涉及到较多的通信(使用 IPC),从而需要更多的开销。比如为了让 shell 能与 FS 交互,shell 需要向 kernel 的 IPC 发送一条 message,kernel 查看这个 message 并发现这是给 FS 的消息,之后 kernel 会将这个 message 转发给 FS,FS 完成工作后会向 kernel 的 IPC 发送一条 message 返回结果,kernel 再将其转发给 shell。这就是典型的通过消息来实现传统的 system call。可以看到,原本在宏内核下程序与 FS 的交互只需要一次 user mode <-> kernel mode 的切换,现在微内核下变成了两次切换,性能变得更差了。
这里是 OS 的两种主要设计。xv6 与大多数 Unix 系统一样,都是宏内核设计,但在后半学期也会讨论更多有关微内核的设计。