 异步机制、CPU 架构对性能的影响
异步机制、CPU 架构对性能的影响
参考:
Redis 因其高性能而被广泛应用,我们需要避免性能异常的情况出现。影响 Redis 性能的 5 大方面因素有:
- Redis 内部的阻塞式操作
- CPU 核和 NUMA 架构的影响
- Redis 关键系统配置
- Redis 内存碎片
- Redis 缓冲区
本文将分析前两个因素。
# 1. 异步机制:如何避免单线程模型的阻塞?
# 1.1 Redis 实例有哪些阻塞点?
Redis 的网络 IO 和键值对读写是由主线程完成的,这些不同的交互要涉及不同的操作。我们看一下 Redis 有哪些交互操作:
- 客户端:网络 IP、KV 的 CRUD 等
- 磁盘:AOF 与 RDB 操作
- 主从节点:数据复制操作
- 切片集群:向其他实例传输哈希槽信息、数据迁移
这四类交互对象和操作之间的关系如下图:
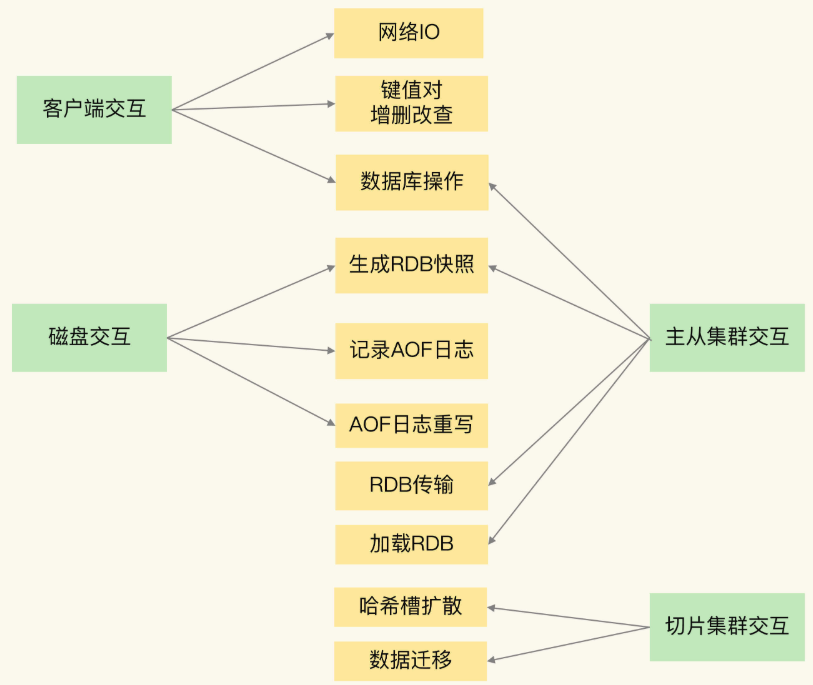
下面我们逐个分析哪些操作会引起阻塞:
# 1)和客户端交互时的阻塞点
由于 Redis 使用了 IO 多路复用机制避免了主线程的一直等待,所以网络 IO 不是导致 Redis 阻塞的因素。
CRUD 操作是 Redis 与客户端交互的主要部分,也是 Redis 主线程执行的主要任务。所以,复杂度高的增删改查操作肯定会阻塞 Redis。
那怎么判断操作复杂度高不高呢?这里有一个最基本的标准,就是看操作的复杂度是否为 O(N)。
Redis中涉及集合的操作复杂度通常为O(N),我们要在使用时重视起来。例如集合元素全量查询操作HGETALL、SMEMBERS,以及集合的聚合统计操作,例如求交、并和差集。这些操作可以作为 Redis 的第一个阻塞点:集合全量查询和聚合操作。
除此之外,集合自身的删除操作同样也有潜在的阻塞风险。因为删除操作的本质是要释放键值对占用的内存空间,而操作系统在释放内存时需要把所释放的内存块插入空闲链表中以便管理,这个过程可能会阻塞程序。所以,如果一下子释放了大量内存,空闲内存块链表操作时间就会增加,相应地就会造成 Redis 主线程的阻塞。
在删除大量键值对数据的时候,最典型的就是删除包含了大量元素的集合,也称为 bigkey 删除。下图测试了不同元素数量的集合进行删除操作所耗费的时间:
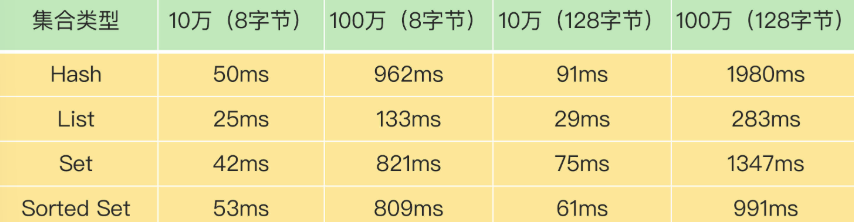
从这张表里,我们可以得出三个结论:
- 当元素数量从10万增加到100万时,4大集合类型的删除时间的增长幅度从5倍上升到了近20倍;
- 集合元素越大,删除所花费的时间就越长;
- 当删除有100万个元素的集合时,最大的删除时间绝对值已经达到了1.98s(Hash类型)。Redis的响应时间一般在微秒级别,所以,一个操作达到了近2s,不可避免地会阻塞主线程。
所以,bigkey 删除操作就是 Redis 的第二个阻塞点。删除操作对Redis实例性能的负面影响很大,而且在实际业务开发时容易被忽略,所以一定要重视它。
小建议
当遇到 bigkey 删除时,有一个小建议:先使用集合类型提供的 SCAN 命令读取数据,然后再进行删除。因为用 SCAN 命令可以每次只读取一部分数据并进行删除,这样可以避免一次性删除大量 key 给主线程带来的阻塞。
例如,对于 Hash 类型的 bigkey 删除,你可以使用 HSCAN 命令,每次从Hash集合中获取一部分键值对(例如200个),再使用 HDEL 删除这些键值对,这样就可以把删除压力分摊到多次操作中,那么,每次删除操作的耗时就不会太长,也就不会阻塞主线程了。
容易联想到,清空数据库(flushdb 和 flushall 操作)也必然是一个潜在的阻塞风险,因为它们也涉及到大量 KV 的删除。所以,Redis 的第三个阻塞点:清空数据库。
# 2)和磁盘交互时的阻塞点
由于磁盘 IO 一般比较慢,因此需要重点关注。Redis 采用子进程的方式来执行 RDB 的生成和 AOF 的重写,从而避免了对主线程的阻塞。
但 Redis 直接记录 AOF 时,会根据不同的写回策略对数据做落盘保存。一次同步写磁盘大约耗时 1~2ms,如果存在大量同步写操作的话,就会阻塞主线程。因此 Redis 的四个阻塞点:AOF 日志同步写。
# 3)主从节点交互时的阻塞点
在主从复制时,从库接收 RDB 文件后,需要使用 flushdb 命令来清空当前数据库,这正好装上了刚刚分析的第三个阻塞点。
此外,从库在清空数据库后,还需要把 RDB 加载到内存中,这个过程与 RDB 文件的大小密切相关,RDB 越大,加载过程越慢。所以,加载 RDB 文件就成为了 Redis 的第五个阻塞点。
# 4)切片集群实例交互时的阻塞点
最后,当我们部署Redis切片集群时,每个Redis实例上分配的哈希槽信息需要在不同实例间进行传递,同时,当需要进行负载均衡或者有实例增删时,数据会在不同的实例间进行迁移。不过,哈希槽的信息量不大,而数据迁移是渐进式执行的,所以,一般来说,这两类操作对 Redis 主线程的阻塞风险不大。
不过,如果你使用了 Redis Cluster 方案,而且同时正好迁移的是 bigkey 的话,就会造成主线程的阻塞,因为 Redis Cluster 使用了同步迁移。我将在第33讲中向你介绍不同切片集群方案对数据迁移造成的阻塞的解决方法,这里你只需要知道,当没有 bigkey 时,切片集群的各实例在进行交互时不会阻塞主线程,就可以了。
现在我们总结了刚刚找到的五个阻塞点:
- 集合全量查询和聚合操作
- bigkey 删除
- 清空数据库
- AOF 日志同步写
- 从库加载 RDB 文件
如果在主线程中执行这些操作,必然会导致主线程长时间无法服务其他请求。为了避免阻塞式操作,Redis 提供了异步线程机制。所谓的异步线程机制:指 Redis 会启动一些子线程,然后把一些任务交给这些子线程,让它们在后台完成,而不再由主线程来执行这些任务。使用异步线程机制执行操作,可以避免阻塞主线程。
不过问题来了,这五个阻塞式操作都可以被异步执行吗?
# 1.2 哪些阻塞点可以异步执行?
先看一下异步执行对操作的要求。
如果一个操作能被异步执行,就意味着,它并不是 Redis 主线程的关键路径上的操作。关键路径上的操作是说,客户端把请求发给 Redis 后就等着返回数据结果。如下图:
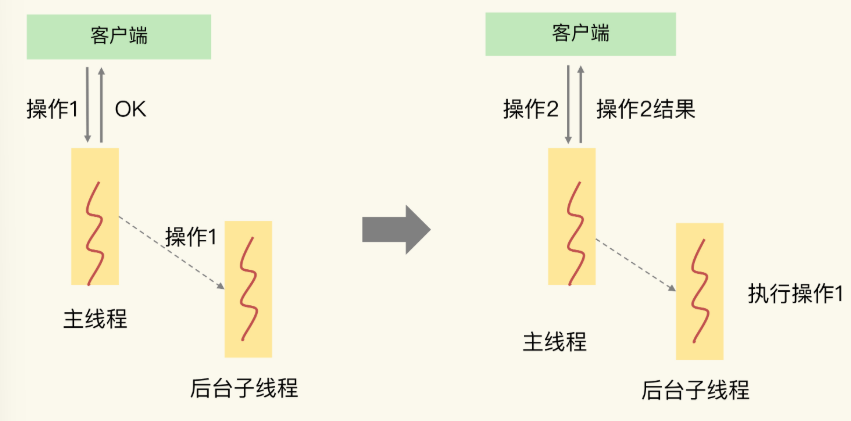
- 左图的操作 1 就不算关键路径上的操作,因此可以让后台子线程来异步执行;
- 右图的操作 2 就是关键路径上的操作,所以主线程必须立即把这个操作执行完。
对 Redis 来说,读操作是典型的关键路径操作。Redis 的第一个阻塞点“集合全量查询和聚合操作”都涉及到了读操作,所以,它们是不能进行异步操作了。
而删除操作不需要立刻返回具体的结果,不算是关键路径操作,因此我们可以使用后台子线程来异步执行删除操作。
对于第四个阻塞点“AOF日志同步写”来说,为保证数据可靠性,Redis 实例需要保证 AOF 日志中的操作记录已经落盘,这个操作虽然需要实例等待,但它并不会返回具体的数据结果给实例。所以,我们也可以启动一个子线程来执行AOF日志的同步写,而不用让主线程等待AOF日志的写完成。
最后再看下“从库加载 RDB 文件”这个阻塞点。从库必须把 RDB 加载完,这操作也属于关键路径上的操作,所以我们必须让从库的主线程来执行。
对于 Redis 的五大阻塞点来说,除了“集合全量查询和聚合操作”和“从库加载 RDB 文件”,其他三个阻塞点涉及的操作都不在关键路径上,所以可以使用 Redis 的异步子线程机制来实现 bigkey 删除,清空数据库,以及 AOF 日志同步写。
小建议
集合全量查询和聚合操作、从库加载RDB文件是在关键路径上,无法使用异步操作来完成。对于这两个阻塞点也有两个小建议:
- 集合全量查询和聚合操作:可以使用 SCAN 命令,分批读取数据,再在客户端进行聚合计算;
- 从库加载 RDB 文件:把主库的数据量大小控制在 2~4GB 左右,以保证 RDB 文件能以较快的速度加载。
那 Redis 实现的异步子线程机制具体是怎么执行呢?
# 1.3 异步的子线程机制
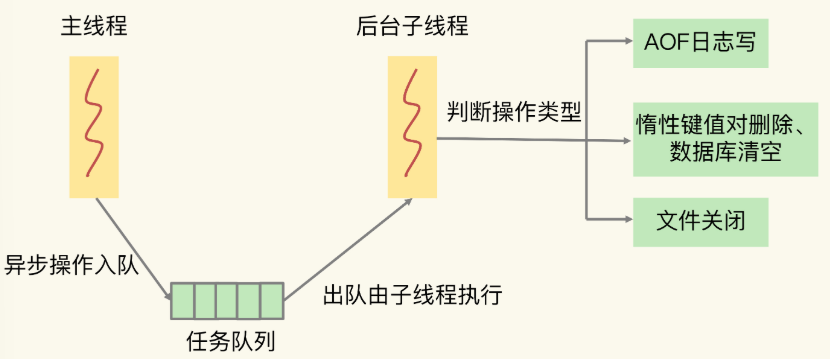
Redis 主线程启动后,会使用操作系统提供的 pthread_create 函数创建 3 个子线程,分别由它们负责 AOF 日志写操作、键值对删除以及文件关闭的异步执行。
主线程通过一个链表形式的任务队列和子线程进行交互。当收到键值对删除和清空数据库的操作时,主线程会把这个操作封装成一个任务,放入到任务队列中,然后给客户端返回一个完成信息,表明删除已经完成。但实际上,这个时候删除还没有执行,等到后台子线程从任务队列中读取任务后,才开始实际删除键值对,并释放相应的内存空间。因此,我们把这种异步删除也称为惰性删除(lazy free)。此时,删除或清空操作不会阻塞主线程,这就避免了对主线程的性能影响。
和惰性删除类似,当 AOF 日志配置成 everysec 选项后,主线程会把 AOF 写日志操作封装成一个任务,也放到任务队列中。后台子线程读取任务后,开始自行写入 AOF 日志,这样主线程就不用一直等待 AOF 日志写完了。
下面这张图展示了 Redis 中的异步子线程执行机制:
异步的键值对删除和数据库清空操作是 Redis 4.0 后提供的功能,Redis也提供了新的命令来执行这两个操作:
- 键值对删除:当你的集合类型中有大量元素(例如有百万级别或千万级别元素)需要删除时,我建议你使用 UNLINK 命令。
- 清空数据库:可以在 FLUSHDB 和 FLUSHALL 命令后加上 ASYNC 选项,这样就可以让后台子线程异步地清空数据库,如下所示:
FLUSHDB ASYNC
FLUSHALL AYSNC
2
# 1.4 小结
这一节主要讲了 Redis 运行时的交互对象和交互操作,并对其中不属于关键路径的操作讲解使用异步子线程机制来完成。
# 2. 为什么 CPU 结构也会影响 Redis 的性能?
CPU 的架构也会影响 Redis 的性能,了解这些对我们的性能调优有很多帮助。
这一节主要学习目前主流 CPU 架构以及基于此优化 Redis 性能的方法。
# 2.1 主流的 CPU 架构
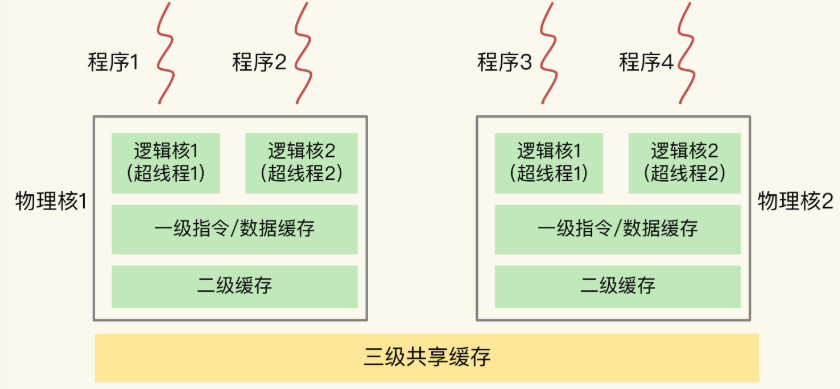
一个 CPU 一般由多个物理核,每个核都可以运行程序,每个核都拥有私有的 L1 cache 和私有的 L2 cache。注意,每个物理核的私有 cache 只能被当前物理核使用。当数据或指令保存在 L1 或 L2 cache 中时,物理核对它们的访问延迟不超过 10 纳秒,速度非常快。
如果 Redis 能把指令或数据存在物理核 cache 中,就能高速访问。但这些 cache 一般只有 KB 级别,放不下太多数据。若 cache 不命中,则需要访问内存,而访存的延迟一般是访问 cache 的 10 倍,不可避免地会对性能造成影响。
所以,不同的物理核还会共享一个共同的 L3 cache。L3 cache 往往较大,能达到几 MB 到几十 MB,从而尽可能避免访问内存。
另外,现在主流的 CPU 中,每个物理核通常都会运行两个超线程,也叫作逻辑核。同一个物理核的逻辑核会共享使用 L1、L2 缓存。
下图展示了物理核、逻辑核、cache 之间的关系:
同时,为了提升服务器的处理能力,服务器还往往会有多个 CPU 处理器,也称多 CPU Socket,每个 CPU Socket 有自己的物理核、L3 cache 以及连接内存,不用 CPU Socket 之间通过总线连接。如下图所示:
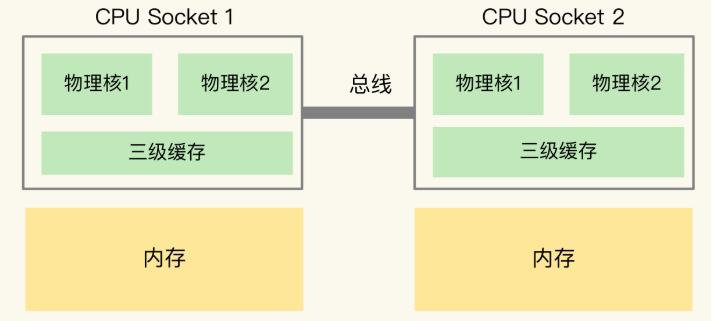
在多CPU架构上,应用程序可以在不同的处理器上运行。在刚才的图中,Redis 可以先在 Socket 1 上运行一段时间,然后再被调度到 Socket 2 上运行。但当程序被调度到 Socket 2 后,再访问内存就需要访问之前 Socket 上连接的内存,这种访问属于远端内存访问。相比访问直接连接的内存,远端内存访问会增加延迟。在多CPU架构下,一个应用程序访问所在 Socket 的本地内存和访问远端内存的延迟并不一致,所以,我们也把这个架构称为非统一内存访问架构(Non-Uniform Memory Access,NUMA 架构)。
到这里,我们就知道了主流的 CPU 多核架构和多 CPU 架构,我们来简单总结下 CPU 架构对应用程序运行的影响:
- 充分利用 L1、L2 cache 可以有效缩短应用程序的执行时间。
- 在 NUMA 架构下,远端内存访问的情况也会增加程序的执行时间。
接下来看一下 CPU 多核是如何影响 Redis 性能的。
# 2.2 CPU 多核对 Redis 性能的影响
程序在不同 CPU 核上切换时,会发生运行时上下文的重新加载,从而导致延迟。
作者就经历过由于 context switch(线程的上下文切换)导致 Redis 的 99% 尾延迟过大。
99% 尾延迟:我们把所有请求的处理延迟从小到大排个序,99%的请求延迟小于的值就是99%尾延迟。比如说,我们有1000个请求,假设按请求延迟从小到大排序后,第991个请求的延迟实测值是1ms,而前990个请求的延迟都小于1ms,所以,这里的99%尾延迟就是1ms。
如果想避免 Redis 总是在不同 CPU 核上来回调度,可以使用 taskset 命令把一个程序绑定在一个核上运行,即绑核。比如下面这条命令把 Redis 实例绑在了 0 号核上,其中,“-c”选项用于设置要绑定的核编号:
taskset -c 0 ./redis-server
下表对比了绑核前后的Redis的99%尾延迟:

绑核不仅对降低尾延迟有好处,同样也能降低平均延迟、提升吞吐率,进而提升 Redis 性能。
# 2.3 CPU 的 NUMA 架构对 Redis 性能的影响
实际应用中,经常看到一种说法:为了提升 Redis 的网络性能,把操作系统的网络中断处理程序和 CPU 核绑定。这个做法可以避免网络中断处理程序在不同核上来回调度执行,的确能有效提升 Redis 的网络处理性能。但是,网络中断程序是要和 Redis 实例进行网络数据交互的,一旦把网络中断程序绑核后,我们就需要注意 Redis 实例是绑在哪个核上了,这会关系到 Redis 访问网络数据的效率高低。
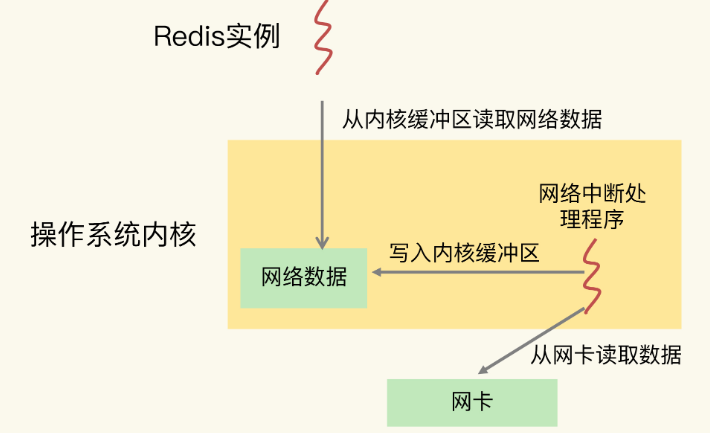
我们先来看下Redis实例和网络中断程序的数据交互:网络中断处理程序从网卡硬件中读取数据,并把数据写入到操作系统内核维护的一块内存缓冲区。内核会通过epoll机制触发事件,通知Redis实例,Redis实例再把数据从内核的内存缓冲区拷贝到自己的内存空间,如下图所示:
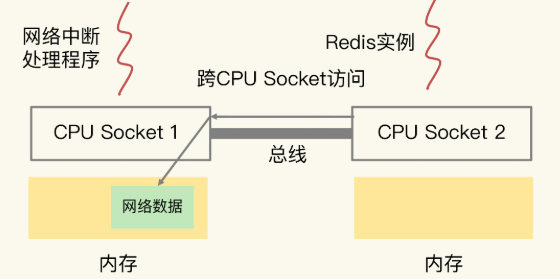
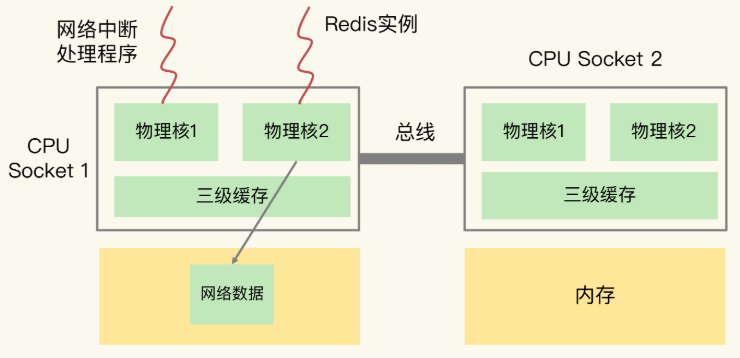
那么,在CPU的NUMA架构下,当网络中断处理程序、Redis实例分别和CPU核绑定后,就会有一个潜在的风险:如果网络中断处理程序和 Redis 实例没有绑定到同一 CPU Socket 上,那 Redis 读取网络数据时,就需要跨 CPU Socket 访问内存,这个过程会花费较多时间。如下图所示:
为了避免 Redis 跨 CPU Socket 访问,我们最好把网络中断程序和Redis实例绑在同一个 CPU Socket 上。如下图所示:
CPU Socket 的编号可以通过 lscpu 命令来查看:
$ lscpu
Architecture: x86_64
...
NUMA node0 CPU(s): 0-5,12-17
NUMA node1 CPU(s): 6-11,18-23
...
2
3
4
5
6
7
- 可以看到,NUMA node0的CPU核编号是0到5、12到17。其中,0到5是node0上的6个物理核中的第一个逻辑核的编号,12到17是相应物理核中的第二个逻辑核编号。NUMA node1的CPU核编号规则和node0一样。
不过,绑核也存在一定的风险。接下来就来了解下它的潜在风险点和解决方案。
# 2.4 绑核的风险和解决方案
Redis 除了主线程以外,还有许多子进程和后台线程,当我们把 Redis 实例绑核后,可能会导致子进程、后台线程和 Redis 主线程竞争 CPU 资源,从而导致 Redis 请求延迟增加。
针对这种情况有两个解决方案:
# 方案一:一个 Redis 实例对应绑一个物理核
在给 Redis 实例绑核时,我们不要把一个实例和一个逻辑核绑定,而要和一个物理核绑定,也就是说,把一个物理核的 2 个逻辑核都用上。
我们还是以刚才的NUMA架构为例,NUMA node0的CPU核编号是0到5、12到17。其中,编号0和12、1和13、2和14等都是表示一个物理核的2个逻辑核。所以,在绑核时,我们使用属于同一个物理核的2个逻辑核进行绑核操作。例如,我们执行下面的命令,就把Redis实例绑定到了逻辑核0和12上,而这两个核正好都属于物理核1。
taskset -c 0,12 ./redis-server
和只绑一个逻辑核相比,把 Redis 实例和物理核绑定,可以让主线程、子进程、后台线程共享使用2个逻辑核,可以在一定程度上缓解 CPU 资源竞争。但是,因为只用了 2 个逻辑核,它们相互之间的 CPU 竞争仍然还会存在。如果你还想进一步减少 CPU 竞争,还有另一种方案。
# 方案二:优化 Redis 源码
这个方案就是通过修改Redis源码,把子进程和后台线程绑到不同的CPU核上。
如果你对Redis的源码不太熟悉,也没关系,因为这是通过编程实现绑核的一个通用做法。学会了这个方案,你可以在熟悉了源码之后把它用上,也可以应用在其他需要绑核的场景中。
接下来,我先介绍一下通用的做法,然后,再具体说说可以把这个做法对应到Redis的哪部分源码中。
通过编程实现绑核时,要用到操作系统提供的1个数据结构cpu_set_t和3个函数CPU_ZERO、CPU_SET和sched_setaffinity,我先来解释下它们。
- cpu_set_t数据结构:是一个位图,每一位用来表示服务器上的一个CPU逻辑核。
- CPU_ZERO函数:以cpu_set_t结构的位图为输入参数,把位图中所有的位设置为0。
- CPU_SET函数:以CPU逻辑核编号和cpu_set_t位图为参数,把位图中和输入的逻辑核编号对应的位设置为1。
- sched_setaffinity函数:以进程/线程ID号和cpu_set_t为参数,检查cpu_set_t中哪一位为1,就把输入的ID号所代表的进程/线程绑在对应的逻辑核上。
那么,怎么在编程时把这三个函数结合起来实现绑核呢?很简单,我们分四步走就行。
- 第一步:创建一个cpu_set_t结构的位图变量;
- 第二步:使用CPU_ZERO函数,把cpu_set_t结构的位图所有的位都设置为0;
- 第三步:根据要绑定的逻辑核编号,使用CPU_SET函数,把cpu_set_t结构的位图相应位设置为1;
- 第四步:使用sched_setaffinity函数,把程序绑定在cpu_set_t结构位图中为1的逻辑核上。
下面,我就具体介绍下,分别把后台线程、子进程绑到不同的核上的做法。
先说后台线程。为了让你更好地理解编程实现绑核,你可以看下这段示例代码,它实现了为线程绑核的操作:
//线程函数
void worker(int bind_cpu){
cpu_set_t cpuset; //创建位图变量
CPU_ZERO(&cpu_set); //位图变量所有位设置0
CPU_SET(bind_cpu, &cpuset); //根据输入的bind_cpu编号,把位图对应为设置为1
sched_setaffinity(0, sizeof(cpuset), &cpuset); //把程序绑定在cpu_set_t结构位图中为1的逻辑核
//实际线程函数工作
}
int main(){
pthread_t pthread1
//把创建的pthread1绑在编号为3的逻辑核上
pthread_create(&pthread1, NULL, (void *)worker, 3);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
对于Redis来说,它是在bio.c文件中的bioProcessBackgroundJobs函数中创建了后台线程。bioProcessBackgroundJobs函数类似于刚刚的例子中的worker函数,在这个函数中实现绑核四步操作,就可以把后台线程绑到和主线程不同的核上了。
和给线程绑核类似,当我们使用fork创建子进程时,也可以把刚刚说的四步操作实现在fork后的子进程代码中,示例代码如下:
int main(){
//用fork创建一个子进程
pid_t p = fork();
if(p < 0){
printf(" fork error\n");
}
//子进程代码部分
else if(!p){
cpu_set_t cpuset; //创建位图变量
CPU_ZERO(&cpu_set); //位图变量所有位设置0
CPU_SET(3, &cpuset); //把位图的第3位设置为1
sched_setaffinity(0, sizeof(cpuset), &cpuset); //把程序绑定在3号逻辑核
//实际子进程工作
exit(0);
}
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
对于Redis来说,生成RDB和AOF日志重写的子进程分别是下面两个文件的函数中实现的。
- rdb.c文件:rdbSaveBackground函数;
- aof.c文件:rewriteAppendOnlyFileBackground函数。
这两个函数中都调用了fork创建子进程,所以,我们可以在子进程代码部分加上绑核的四步操作。
使用源码优化方案,我们既可以实现Redis实例绑核,避免切换核带来的性能影响,还可以让子进程、后台线程和主线程不在同一个核上运行,避免了它们之间的CPU资源竞争。相比使用taskset绑核来说,这个方案可以进一步降低绑核的风险。
# 2.5 小结
这一节讲了主流的 CPU 架构以及 NUMA 架构,并解释了 CPU 对 Redis 性能的影响。
- 由于 CPU Socket 之间的切换会增加尾延迟,因此建议把实例与某个核进行绑定。
- 为提升 Redis 的网络性能,有时需要把网络中断处理程序和 CPU 核绑定。
- 为防止绑核导致 Redis 主线程与子进程的竞争,本文提出了两种方案来解决。
Redis 的低延迟是我们永恒的追求目标,而多核 CPU 和 NUMA 架构已经成为了目前服务器的主流配置。所以绑核优化方案在实践中很重要。