 如何应对变慢的 Redis
如何应对变慢的 Redis
参考:
在实际部署中,有一个很严重的问题:Redis 突然变慢了,这可能会直接影响其他系统,导致一连串的连锁反应。本文将介绍如何系统性地应对 Redis 变慢这个问题,并从问题认定、系统性排查和应对方案这 3 个方面来进行讲解。
# 1. Redis 真的变慢了吗?
判断 Redis 是否真的变慢了有个最直接的方法:查看 Redis 的响应延迟。
大部分时候 Redis 延迟很低,但某些时刻可能会出现很高的相应延迟,甚至能达到几秒到十几秒,不过持续时间不长,这也叫延迟毛刺。当你发现 Redis 命令的执行时间突然就增长到了几秒,基本就可以认定 Redis 变慢了。
这种方法看的是 Redis 延迟的绝对值,但在不同的软硬件环境下,Redis 的绝对性能本身并不相同。比如差的机器延迟 1ms 才认定变慢了,但好的机器延迟 0.2ms 就可以认定变慢了。
所以需要第二个判断方法:基于当前环境下的 Redis 基线性能做判断。基线性能:指一个系统在低压力、无干扰下的基本性能,这个性能只由当前的软硬件配置决定。
具体如何确定基线性能呢?redis-cli 命令提供了 –intrinsic-latency 选项,可以用来监测和统计测试期间内的最大延迟,这个延迟可以作为 Redis 的基线性能。其中,测试时长可以用 –intrinsic-latency 选项的参数来指定。
举个例子,比如说,我们运行下面的命令,该命令会打印 120 秒内监测到的最大延迟。可以看到,这里的最大延迟是 119 微秒,也就是基线性能为 119 微秒。一般情况下,运行 120 秒就足够监测到最大延迟了,所以,我们可以把参数设置为 120。
./redis-cli --intrinsic-latency 120
Max latency so far: 17 microseconds.
Max latency so far: 44 microseconds.
Max latency so far: 94 microseconds.
Max latency so far: 110 microseconds.
Max latency so far: 119 microseconds.
36481658 total runs (avg latency: 3.2893 microseconds / 3289.32 nanoseconds per run).
Worst run took 36x longer than the average latency.
2
3
4
5
6
7
8
9
一般来说,你要把运行时延迟和基线性能进行对比,如果你观察到的 Redis 运行时延迟是其基线性能的 2 倍及以上,就可以认定 Redis 变慢了。
我们通常是通过客户端和网络访问Redis服务,为了避免网络对基线性能的影响,刚刚说的这个命令需要在服务器端直接运行,这也就是说,我们只考虑服务器端软硬件环境的影响。如果你想了解网络对Redis性能的影响,一个简单的方法是用 iPerf 这样的工具,测量从 Redis 客户端到服务器端的网络延迟。如果这个延迟有几十毫秒甚至是几百毫秒,就说明,Redis 运行的网络环境中很可能有大流量的其他应用程序在运行,导致网络拥塞了。这个时候,你就需要协调网络运维,调整网络的流量分配了。
# 2. 如何应对 Redis 变慢?
我们现在需要诊断 Redis 变慢的原因。下图是 Redis 的架构图,红色模块就是影响 Redis 的三大要素:Redis 自身的操作特性、文件系统和操作系统。
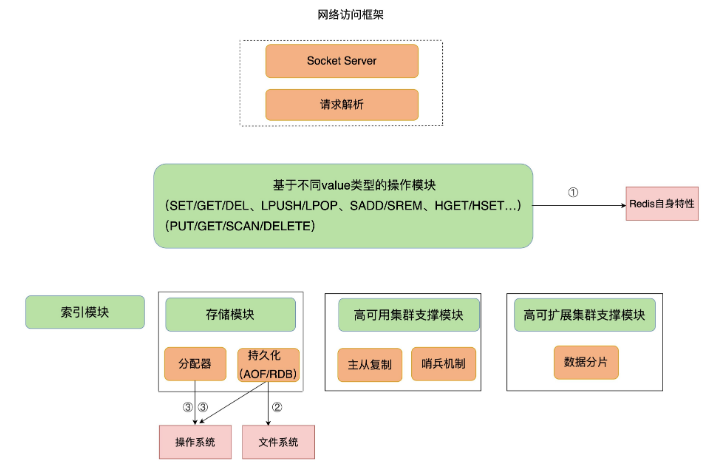
下面将从这三大要素入手,并结合实际的应用场景,依次介绍从不同要素出发排查和解决问题的实践经验。性能诊断通常是一件困难的事,所以我们一定不能毫无目标地“乱找”。
# 2.1 Redis 自身操作特性的影响
首先来学习下 Redis 提供的键值对命令操作对延迟性能的影响。这里重点介绍两类关键操作:慢查询命令和过期 key 操作。
# 2.1.1 慢查询命令
慢查询命令:指在 Redis 中执行速度慢的命令,这会导致 Redis 延迟增加。
执行快慢与操作复杂度相关。比如说,Value 类型为 String 时,GET/SET 操作主要就是操作 Redis 的哈希表索引。这个操作复杂度基本是固定的,即 O(1)。但是,当 Value 类型为 Set 时,SORT、SUNION/SMEMBERS 操作复杂度分别为 O(N+M*log(M)) 和 O(N) 。其中,N 为 Set 中的元素个数,M 为 SORT 操作返回的元素个数。这个复杂度就增加了很多。Redis官方文档 (opens new window) 中对每个命令的复杂度都有介绍,当你需要了解某个命令的复杂度时,可以直接查询。
当你发现 Redis 性能变慢时,可以通过 Redis 日志,或者是 latency monitor 工具,查询变慢的请求,根据请求对应的具体命令以及官方文档,确认下是否采用了复杂度高的慢查询命令。如果的确有大量的慢查询命令,有两种处理方式:
- 用其他高效命令代替。比如说,如果你需要返回一个SET中的所有成员时,不要使用SMEMBERS命令,而是要使用SSCAN多次迭代返回,避免一次返回大量数据,造成线程阻塞。
- 当你需要执行排序、交集、并集操作时,可以在客户端完成,而不要用 SORT、SUNION、SINTER 这些命令,以免拖慢 Redis 实例。
还有一个比较容易忽略的慢查询命令,就是 KEYS:用于返回和输入模式匹配的所有key。例如,以下命令返回所有包含“name”字符串的 keys:
redis> KEYS *name*
1) "lastname"
2) "firstname"
2
3
因为 KEYS 命令需要遍历存储的键值对,所以操作延时高。如果你不了解它的实现而使用了它,就会导致Redis性能变慢。所以,KEYS命令一般不被建议用于生产环境中。
# 2.1.2 过期 key 操作
过期 key 的自动删除机制是 Redis 用来回收内存空间的常用机制,应用广泛,本身就会引起Redis操作阻塞,导致性能变慢,所以,你必须要知道该机制对性能的影响。
Redis 键值对的 key 可以设置过期时间。默认情况下,Redis 每 100 毫秒会删除一些过期 key,具体的算法如下:
- 采样 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 个数的 key,并将其中过期的 key 全部删除;
- 如果超过 25% 的 key 过期了,则重复删除的过程,直到过期 key 的比例降至 25% 以下。
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 是 Redis 的一个参数,默认是 20,那么,一秒内基本有 200 个过期 key 会被删除。这一策略对清除过期 key、释放内存空间很有帮助。如果每秒钟删除 200 个过期 key,并不会对 Redis 造成太大影响。
但是,如果触发了上面这个算法的第二条,Redis 就会一直删除以释放内存空间。注意,删除操作是阻塞的(Redis 4.0后可以用异步线程机制来减少阻塞影响)。所以,一旦该条件触发,Redis 的线程就会一直执行删除,这样一来,就没办法正常服务其他的键值操作了,就会进一步引起其他键值操作的延迟增加,Redis 就会变慢。
算法的第二条被触发的一个重要来源就是:频繁使用带有相同时间参数的 EXPIREAT 命令设置过期 key,这就会导致,在同一秒内有大量的 key 同时过期。这里我就要给出第二条排查建议和解决方法了:
你要检查业务代码在使用 EXPIREAT 命令设置 key 过期时间时,是否使用了相同的 UNIX 时间戳,有没有使用 EXPIRE 命令给批量的 key 设置相同的过期秒数。因为,这都会造成大量 key 在同一时间过期,导致性能变慢。
遇到这种情况时,千万不要嫌麻烦,你首先要根据实际业务的使用需求,决定 EXPIREAT 和 EXPIRE 的过期时间参数。其次,如果一批 key 的确是同时过期,你还可以在 EXPIREAT 和 EXPIRE 的过期时间参数上,加上一个一定大小范围内的随机数,这样,既保证了 key 在一个邻近时间范围内被删除,又避免了同时过期造成的压力。
刚刚讲了从 Redis 自身命令操作层面排查的方案,但如果发现 Redis 有执行大量的慢查询命令,也没有同时删除大量过期 keys,那就要关注影响性能的其他机制了,也就是文件系统和操作系统:
- 一方面,Redis 会持久化保存数据到磁盘,这个过程要依赖文件系统来完成,所以,文件系统将数据写回磁盘的机制,会直接影响到 Redis 持久化的效率。而且,在持久化的过程中,Redis 也还在接收其他请求,持久化的效率高低又会影响到 Redis 处理请求的性能。
- 另一方面,Redis是内存数据库,内存操作非常频繁,所以,操作系统的内存机制会直接影响到 Redis 的处理效率。比如说,如果 Redis 的内存不够用了,操作系统会启动 swap 机制,这就会直接拖慢 Redis。
# 2.2 文件系统:AOF 模式
为了保证数据可靠性,Redis会采用AOF日志或RDB快照。其中,AOF 日志提供了三种日志写回策略:no、everysec、always。这三种写回策略依赖文件系统的两个系统调用完成,也就是 write 和 fsync:
- write 只要把日志记录写到内核缓冲区,就可以返回了,并不需要等待日志实际写回到磁盘;
- fsync 需要把日志记录写回到磁盘后才能返回,时间较长。
下表展示了三种写回策略所执行的系统调用:

当写回策略配置为 everysec 和 always 时,Redis 需要调用 fsync 把日志写回磁盘。但是,这两种写回策略的具体执行情况还不太一样:
- 在使用everysec时,Redis允许丢失一秒的操作记录,所以,Redis主线程并不需要确保每个操作记录日志都写回磁盘。而且,fsync的执行时间很长,如果是在Redis主线程中执行fsync,就容易阻塞主线程。所以,当写回策略配置为everysec时,Redis会使用后台的子线程异步完成fsync的操作。
- 而对于always策略来说,Redis需要确保每个操作记录日志都写回磁盘,如果用后台子线程异步完成,主线程就无法及时地知道每个操作是否已经完成了,这就不符合always策略的要求了。所以,always策略并不使用后台子线程来执行。
另外,在使用AOF日志时,为了避免日志文件不断增大,Redis会执行AOF重写,生成体量缩小的新的AOF日志文件。AOF重写本身需要的时间很长,也容易阻塞Redis主线程,所以,Redis使用子进程来进行AOF重写。
但是,这里有一个潜在的风险点:AOF 重写会对磁盘进行大量 IO 操作,同时,fsync 又需要等到数据写到磁盘后才能返回,所以,当 AOF 重写的压力比较大时,就会导致 fsync 被阻塞。虽然fsync是由后台子线程负责执行的,但是,主线程会监控fsync的执行进度。
当主线程使用后台子线程执行了一次fsync,需要再次把新接收的操作记录写回磁盘时,如果主线程发现上一次的fsync还没有执行完,那么它就会阻塞。所以,如果后台子线程执行的fsync频繁阻塞的话(比如AOF重写占用了大量的磁盘IO带宽),主线程也会阻塞,导致Redis性能变慢。
下图展示了在磁盘压力小和压力大的时候,fsync后台子线程和主线程受到的影响:
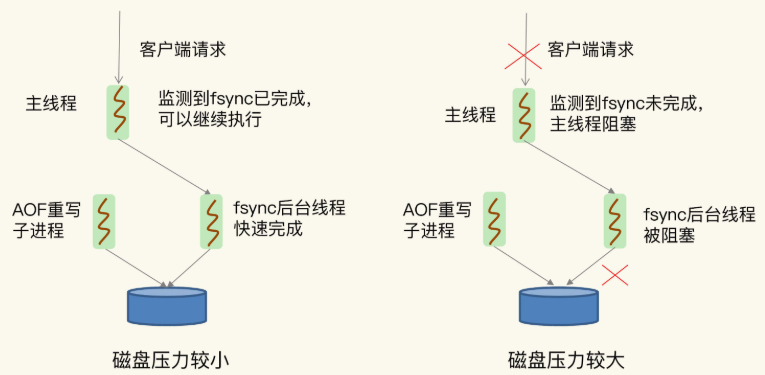
到这里你应该可以了解了,由于 fsync 后台子线程和 AOF 重写子进程的存在,主 IO 线程一般不会被阻塞。但是,如果在重写日志时,AOF 重写子进程的写入量比较大,fsync 线程也会被阻塞,进而阻塞主线程,导致延迟增加。
现在,我来给出排查和解决建议。
首先,你可以检查下 Redis 配置文件中的 appendfsync 配置项,该配置项的取值表明了 Redis 实例使用的是哪种 AOF 日志写回策略,如下所示:

如果 AOF 写回策略使用了 everysec 或 always 配置,请先确认下业务方对数据可靠性的要求,明确是否需要每一秒或每一个操作都记日志。有的业务方不了解 Redis AOF 机制,很可能就直接使用数据可靠性最高等级的 always 配置了。其实,很多场景中 Redis 只是作为缓存,并不需要很高的数据可靠性。
如果业务应用对延迟非常敏感,但同时允许一定量的数据丢失,那么,可以把配置项 no-appendfsync-on-rewrite 设置为 yes。这样表示在 AOF 重写时,不进行 fsync 操作。也就是说,Redis 实例把写命令写到内存后,不调用后台线程进行 fsync 操作,就可以直接返回了。当然,如果此时实例发生宕机,就会导致数据丢失。反之,如果这个配置项设置为 no(也是默认配置),在 AOF 重写时,Redis 实例仍然会调用后台线程进行 fsync 操作,这就会给实例带来阻塞。
如果的确需要高性能,同时也需要高可靠数据保证,那建议考虑采用高速的固态硬盘作为AOF日志的写入设备。高速固态盘的带宽和并发度比传统的机械硬盘的要高出10倍及以上。在AOF重写和fsync后台线程同时执行时,固态硬盘可以提供较为充足的磁盘IO资源,让AOF重写和fsync后台线程的磁盘IO资源竞争减少,从而降低对Redis的性能影响。
# 2.3 操作系统:swap
如果Redis的AOF日志配置只是no,或者就没有采用AOF模式,那么,还会有什么问题导致性能变慢吗?还有一个潜在的瓶颈:操作系统的内存 swap。
内存 swap 是操作系统将内存数据在内存和磁盘间来回换入和换出的机制。由于这涉及磁盘 IO,会导致性能极大地降低。
通常触发 swap 的原因主要是物理机器内存不足,对于 Redis 而言,有两种常见的情况:
- Redis 实例自身使用了大量的内存,导致物理机器的可用内存不足;
- 和 Redis 实例在同一台机器上运行的其他进程,在进行大量的文件读写操作。文件读写本身会占用系统内存,这会导致分配给 Redis 实例的内存量变少,进而触发 Redis 发生 swap。
针对该问题的解决方式:增加机器的内存或者使用 Redis 集群。
操作系统本身会在后台记录每个进程的swap使用情况,即有多少数据量发生了swap。你可以先通过下面的命令查看Redis的进程号,这里是5332:
$ redis-cli info | grep process_id
process_id: 5332
2
然后,进入 Redis 所在机器的 /proc 目录下的该进程目录中:
cd /proc/5332
最后,运行下面的命令,查看该Redis进程的使用情况。在这儿,我只截取了部分结果:
$cat smaps | egrep '^(Swap|Size)'
Size: 584 kB
Swap: 0 kB
Size: 4 kB
Swap: 4 kB
Size: 4 kB
Swap: 0 kB
Size: 462044 kB
Swap: 462008 kB
Size: 21392 kB
Swap: 0 kB
2
3
4
5
6
7
8
9
10
11
每一行Size表示的是Redis实例所用的一块内存大小,而Size下方的Swap和它相对应,表示这块Size大小的内存区域有多少已经被换出到磁盘上了。如果这两个值相等,就表示这块内存区域已经完全被换出到磁盘了。
作为内存数据库,Redis本身会使用很多大小不一的内存块,所以,你可以看到有很多Size行,有的很小,就是4KB,而有的很大,例如462044KB。不同内存块被换出到磁盘上的大小也不一样,例如刚刚的结果中的第一个4KB内存块,它下方的Swap也是4KB,这表示这个内存块已经被换出了;另外,462044KB这个内存块也被换出了462008KB,差不多有462MB。
这里有个重要的地方,我得提醒你一下,当出现百MB,甚至GB级别的swap大小时,就表明,此时,Redis实例的内存压力很大,很有可能会变慢。所以,swap 的大小是排查 Redis 性能变慢是否由 swap 引起的重要指标。
一旦发生内存swap,最直接的解决方法就是增加机器内存。如果该实例在一个Redis切片集群中,可以增加Redis集群的实例个数,来分摊每个实例服务的数据量,进而减少每个实例所需的内存量。
当然,如果Redis实例和其他操作大量文件的程序(例如数据分析程序)共享机器,你可以将Redis实例迁移到单独的机器上运行,以满足它的内存需求量。如果该实例正好是Redis主从集群中的主库,而从库的内存很大,也可以考虑进行主从切换,把大内存的从库变成主库,由它来处理客户端请求。
# 2.4 操作系统:内存大页
除了内存 swap,还有一个和内存相关的因素,即内存大页机制(Transparent Huge Page, THP),也会影响 Redis 性能。Linux内核从2.6.38开始支持内存大页机制,该机制支持2MB大小的内存页分配,而常规的内存页分配是按4KB的粒度来执行的。
很多人都觉得:“Redis是内存数据库,内存大页不正好可以满足Redis的需求吗?而且在分配相同的内存量时,内存大页还能减少分配次数,不也是对Redis友好吗?”其实内存大页存在一个 trade-off:虽然内存大页可以给Redis带来内存分配方面的收益,但是,不要忘了,Redis为了提供数据可靠性保证,需要将数据做持久化保存。这个写入过程由额外的线程执行,所以,此时,Redis主线程仍然可以接收客户端写请求。客户端的写请求可能会修改正在进行持久化的数据。在这一过程中,Redis就会采用写时复制机制,也就是说,一旦有数据要被修改,Redis并不会直接修改内存中的数据,而是将这些数据拷贝一份,然后再进行修改。如果采用了内存大页,那么,即使客户端请求只修改100B的数据,Redis也需要拷贝2MB的大页。相反,如果是常规内存页机制,只用拷贝4KB。两者相比,你可以看到,当客户端请求修改或新写入数据较多时,内存大页机制将导致大量的拷贝,这就会影响 Redis 正常的访存操作,最终导致性能变慢。
那该怎么办呢?很简单,关闭内存大页就行了。
首先,我们要先排查下内存大页。方法是:在Redis实例运行的机器上执行如下命令:
cat /sys/kernel/mm/transparent_hugepage/enabled
如果执行结果是always,就表明内存大页机制被启动了;如果是never,就表示,内存大页机制被禁止。
在实际生产环境中部署时,我建议你不要使用内存大页机制,操作也很简单,只需要执行下面的命令就可以了:
echo never /sys/kernel/mm/transparent_hugepage/enabled
# 3. 小结
这里梳理了包含 9 个检查点的 checklist,当遇到 Redis 性能变慢时,可以按照这些步骤逐一检查:
- 获取Redis实例在当前环境下的基线性能。
- 是否用了慢查询命令?如果是的话,就使用其他命令替代慢查询命令,或者把聚合计算命令放在客户端做。
- 是否对过期key设置了相同的过期时间?对于批量删除的key,可以在每个key的过期时间上加一个随机数,避免同时删除。
- 是否存在bigkey? 对于bigkey的删除操作,如果你的Redis是4.0及以上的版本,可以直接利用异步线程机制减少主线程阻塞;如果是Redis 4.0以前的版本,可以使用SCAN命令迭代删除;对于bigkey的集合查询和聚合操作,可以使用SCAN命令在客户端完成。
- Redis AOF配置级别是什么?业务层面是否的确需要这一可靠性级别?如果我们需要高性能,同时也允许数据丢失,可以将配置项no-appendfsync-on-rewrite设置为yes,避免AOF重写和fsync竞争磁盘IO资源,导致Redis延迟增加。当然, 如果既需要高性能又需要高可靠性,最好使用高速固态盘作为AOF日志的写入盘。
- Redis实例的内存使用是否过大?发生swap了吗?如果是的话,就增加机器内存,或者是使用Redis集群,分摊单机Redis的键值对数量和内存压力。同时,要避免出现Redis和其他内存需求大的应用共享机器的情况。
- 在Redis实例的运行环境中,是否启用了透明大页机制?如果是的话,直接关闭内存大页机制就行了。
- 是否运行了Redis主从集群?如果是的话,把主库实例的数据量大小控制在2~4GB,以免主从复制时,从库因加载大的RDB文件而阻塞。
- 是否使用了多核CPU或NUMA架构的机器运行Redis实例?使用多核CPU时,可以给Redis实例绑定物理核;使用NUMA架构时,注意把Redis实例和网络中断处理程序运行在同一个CPU Socket上。
实际上,影响系统性能的因素还有很多,这里讲的只是最常见问题的解决方案。
如果你遇到了一些特殊情况,也不要慌,我再给你分享一个小技巧:仔细检查下有没有恼人的邻居,具体点说,就是Redis所在的机器上有没有一些其他占内存、磁盘IO和网络IO的程序,比如说数据库程序或者数据采集程序。如果有的话,我建议你将这些程序迁移到其他机器上运行。为了保证 Redis 高性能,我们需要给 Redis 充足的计算、内存和 IO 资源,给它提供一个“安静”的环境。