 Serverless 与 FaaS
Serverless 与 FaaS
# 1. Serverless 要解决什么问题
一提起 Serverless,总会有一些共性的问题,下面统一回答一下。
# 1.1 三个问题
# 问题 1:说来说去,到底 Serverless 要解决什么问题?
如果我们算一下服务器的开销,当我们想部署一套博客,那么需要我们购买 Linux 虚拟机、数据库、Redis 缓存、负载均衡等等,甚至还要考虑容灾和备份,这么算下来一年最小开销都在 1 万元左右。但如果你用 Serverless 的话,这个成本可以直接降到 1000 元以下。
Serverless 是对运维体系的极端抽象,它给应用开发和部署提供了一个极简模型。这种高度抽象的模型,可以让一个零运维经验的人,几分钟就部署一个 Web 应用上线,并对外提供服务。
所以,你要问我Serverless解决了什么问题,一句话总结就是它可以帮你省钱、省力气。
# 问题 2:为什么阿里巴巴、腾讯这样的公司都在关注 Serverless?
- Serverless 可以有效降低企业中中长尾应用的运营成本。中长尾应用就是那些每天很少很少流量的应用,还包括微服务架构中一些很少被调用到的服务。Serverless 之前,这些中长尾应用至少要独占 1 台虚拟机;现在有了 Serverless 的极速冷启动特性,企业就可以节省这部分开销。
- Serverless 可以提高研发效能。我们后面会讲 Serverless 应用的架构设计,其中,SFF(Serverless For Frontend)可以让前端同学自行负责数据接口的编排,微服务BaaS化则让我们的后端同学更加关注领域设计。可以说,这是一个颠覆性的变化,它能够进一步放大前端工程师的价值。
- Serverless 作为一门新兴技术,未来的想象空间很大。
这里是 GMTC 会议上几个大公司的分享资料,你感兴趣的话,可以先看看:
- 阿里跨境供应链前端架构演进与 Serverless 实践 (opens new window)
- Serverless 前端工程化落地与实践 (opens new window)
- 从前端和云厂商的视角看 Serverless 与未来的开发生态 (opens new window)
# 问题 3:Serverless 对前端工程师来说会有什么机遇?为什么我们要学习 Serverless?
相对其他工种而言,Serverless 给前端工程师带来的机遇更大,它能让前端工程师也享受到云服务的红利。如果说 Node.js 语言的出现解放了一波前端工程师的生产力,那 Node.js+Serverless 又可以进一步激发前端工程师的创造力。
# 1.2 课程的设计
- 基础篇中,我们会讨论 Serverless 要解决的问题,以及 Serverless 的边界和定义。
- 进阶篇中,我们一起学习 FaaS 的后端解决方案 BaaS,以及我们自己现有的后端应用如何 BaaS 化。
- 实践篇中,我会通过 Google 开源的 Kubernetes 向你演示本地化 Serverless 环境如何搭建以及相关技术选型。
# 2. 定义:到底什么是 Serverless?
这一大节将了解一下什么是 Serverless,看看它都能解决哪些问题。
# 2.1 Serverless 能解决什么问题?
Serverless 中:
- Server 指的服务端,它是 Serverless 解决问题的边界。
- less 可以理解为较少关心,它是 Serverless 解决问题的目的。
# 2.1.1 什么是服务端?
这里的服务端就是通常意义上的 Web 后端,如果我们想把它部署到互联网上,就需要服务端的运维知识了。Serverless 解决问题的边界,就是服务端的边界,即服务端运维。
# 2.1.2 服务端运维发展史:从 full 到 less
Serverfull 就是服务端运维全由我们自己负责,Serverless 则是服务端运维较少由我们自己负责,大多数的运维工作交给自动化工具负责。
史前时代:Serverfull。研发和运维隔离,纯人力处理,也就是 Serverfull。 农耕时代:DevOps。DevOps 中研发兼运维,将部署上线和日志抓取的运维工作给工具化了。这样版本控制、线上故障都是由研发处理,更加高效了。 工业时代:Serverless。 建立”代码扫描-测试-灰度验证-上线“的流水线,并利用性能监控+流量估算来解决资源优化和扩缩容的问题。这样,服务端运维工作全部自动化了。
这个发展过程中,运维人员的参与感越来越低,运维的工作都交由了自动化工具来完成,逐渐迈向 NoOps。
但是最终也只是让研发对运维的感知变少,NoOps 只是理想状态,只能无限逼近,所以这个单词是 Serverless,而不是 Server Zero。
# 2.2 到底什么是 Serverless?
在沟通时,对 Serverless 的理解往往需要结合它出现的上下文,主要因为 Serverless 这个词包含的信息量太大,而且适用性很广,但总结来说 Serverless 的含义有这样两种:
- 狭义Serverless(最常见)= Serverless computing架构 = FaaS架构 = Trigger(事件驱动)+ FaaS(函数即服务)+ BaaS(后端即服务,持久化或第三方服务)= FaaS + BaaS
- 广义Serverless = 服务端免运维 = 具备Serverless特性的云服务
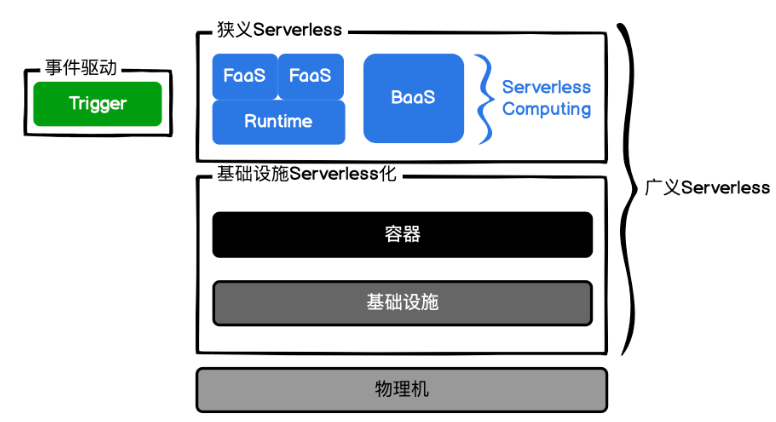
我们经常在工作中提到的Serverless一般都是指狭义的Serverless,因为 14 年 Amazon 推出了第一款 Serverless FaaS 服务:Lambda,这样 Serverless 才进入大多数人的视野,也因此 Serverless 曾经一度就等于 FaaS。
# 2.3 FaaS 和 BaaS
# 2.3.1 FaaS
FaaS,函数即服务,它还有个名字叫作 Serverless Computing,它可以让我们随时随地创建、使用、销毁一个函数。
你可以想一下通常函数的使用过程:它需要先从代码加载到内存,也就是实例化,然后被其它函数调用时执行。在FaaS中也是一样的,函数需要实例化,然后被触发器Trigger或者被其他的函数调用。二者最大的区别就是在 Runtime,也就是函数的上下文,函数执行时的语境。
FaaS的Runtime是预先设置好的,Runtime里面加载的函数和资源都是云服务商提供的,我们可以使用却无法控制。你可以理解为FaaS的Runtime是临时的,函数调用完后,这个临时Runtime和函数一起销毁。
FaaS 的函数调用完后,云服务商会销毁实例,回收资源,所以 FaaS 推荐无状态的函数。如果你是一位前端工程师的话,可能很好理解,就是函数不可改变Immutable。简单解释一下,就是说一个函数只要参数固定,返回的结果也必须是固定的。
在经典 MVC 架构中,View 是客户端展现的内容,通常并不需要函数算力。而 Control 层,就是函数的典型使用场景。MVC 架构里面,一个 HTTP 的数据请求,就会对应一个 Control 函数,我们完全可以用 FaaS 函数来代替 Control 函数。在 HTTP 的数据请求量大的时候,FaaS 函数会自动扩容多实例同时运行;在 HTTP 的数据请求量小时,又会自动缩容;当没有 HTTP 数据请求时,还会缩容到 0 实例,节省开支。
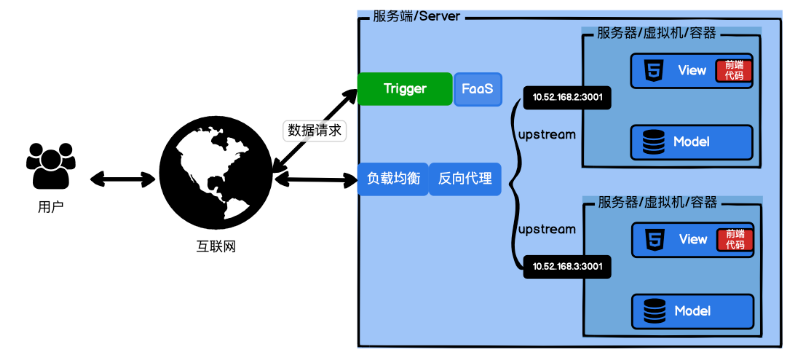
此刻或许你会有点疑惑,Runtime 不可控,FaaS 函数无状态,函数的实例又不停地扩容缩容,那我需要持久化存储一些数据怎么办,MVC 里面的 Model 层怎么解决?此时便要介绍另一位嘉宾:BaaS。
# 2.3.2 BaaS
BaaS 其实是一个集合,是指具备高可用性和弹性,而且免运维的后端服务。
MVC架构中的Model层,就需要我们用BaaS来解决。Model层我们以MySQL为例,后端服务最好是将FaaS操作的数据库的命令,封装成HTTP的OpenAPI,提供给FaaS调用,自己控制这个API的请求频率以及限流降级。这个后端服务本身则可以通过连接池、MySQL集群等方式去优化。各大云服务商自身也在改造自己的后端服务,BaaS这个集合也在日渐壮大。
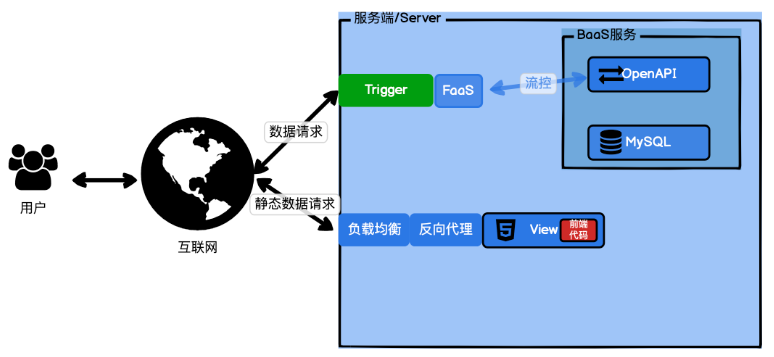
基于 Serverless 架构,我们完全可以把传统的 MVC 架构转换为 BaaS+View+FaaS 的组合,重构或实现。
Serverless毋庸置疑正是因为FaaS架构才流行起来,进入大家认知的。所以我们最常见的Serverless都是指Serverless Computing架构,也就是由Trigger、FaaS和BaaS架构组成的应用。这也是我给出的狭义Serverless的定义。
而广义的 Serverless 的含义,就是指服务端免运维,这也是未来的主要趋势。
总结来说的话就是,我们日常谈Serverless的时候,基本都是指狭义的Serverless,但当我们提到某个服务Serverless化的时候,往往都是指广义的Serverless。我们后面的课程中也是如此。
# 3. 通过一个案例,理解 FaaS 的运行逻辑
上一节从概念的角度对 Serverless 有了一个了解,这一节将通过快速部署纯 FaaS 的 Serverless 应用来讲一下 FaaS 应用背后的运行原理。