 爬虫基础
爬虫基础
详细细节可以单独搜索具体的内容。
# 1. HTTP 基本原理
# 1.1 URL
URL 基本格式:scheme://[username:password@]hostname[:port][/path][;parameters][?query][#fragment]
- scheme:指定使用的传输协议,如 http
- hostname:是指存放资源的服务器的域名系统 (DNS) 主机名或 IP 地址。
- port:省略时使用协议的默认端口号
- query:用于给动态网页传递参数,可有多个参数,用“&”符号隔开,每个参数的名和值用“=”符号隔开。
- fragment:是对资源描述的部分补充。目前有两个主要用途:一个是用作单页面路由,如 Vue、React 都借助它来做路由管理;一个是用作 HTML 锚点,用它可以控制一个页面打开时自动滚动到某个特定的位置。
# 1.2 HTTP 与 HTTPS
HTTP 下加入 SSL 安全层,便成为 HTTPS。目前 HTTPS 是大势所趋。
# 1.3 HTTP 请求过程
在浏览器中快捷键 F12 打开浏览器的开发者工具,进入 Network 页面,下方的每一个条目表示一次发送请求和接收响应的过程:
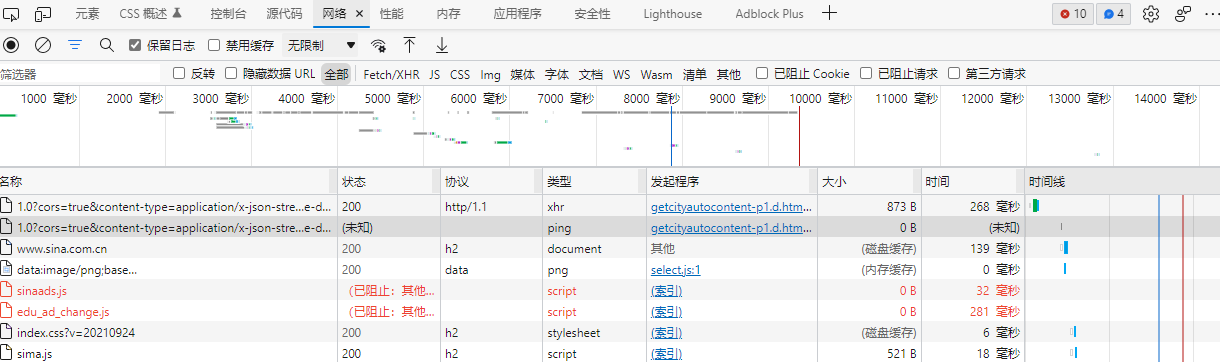
- 协议:其中 h2 代表 HTTP 2.0 版本。
- 类型:其中 document 代表这是一个 HTML 文档。
- 发起程序(Initiator):标记请求是由哪个对象或进程发起的
- 大小:请求资源的大小,如果资源是从缓存中取得的,则该列会显示 from cache
# 1.4 HTTP 请求
Request 分为请求行(request line)、请求头部(header)、空行和请求数据:
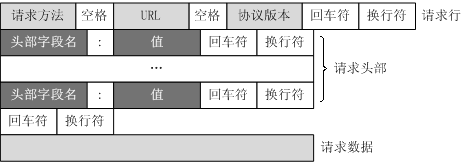
# 请求头
比较重要的信息有 Cookie、Referer、User-Agent 等。
- Referer:表示这个请求是从哪个URL过来的,假如你通过google搜索出一个商家的广告页面,你对这个广告页面感兴趣,鼠标一点发送一个请求报文到商家的网站,这个请求报文的Referer报文头属性值就是
http://www.google.com。。 - User-Agent:用于识别客户端的浏览器等的信息。做爬虫时如果加上这个信息,可以伪装成浏览器;如果不加,很可能会被识别出来。
- Content-Type:决定浏览器将以什么形式、什么编码读取这个文件。比如 text/html 表示 HTML 格式,image/gif 代表 GIF 图片,application/json 代表 JSON 类型,application/x-www-form-urlencoded 代表表单数据。做爬虫时,构造 POST 请求需要使用正确的 Content-Type 才能使参数请求成功。
# 1.5 HTTP 响应
Response 也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
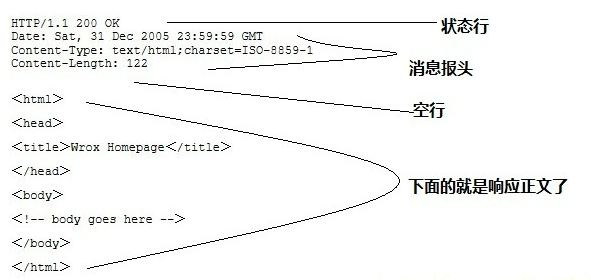
响应状态码表示服务器的响应状态,如 200 表示正常响应。做爬虫时,我们可以根据状态码来判断服务器的响应状态,如 status 为 200 证明成功返回数据,否则直接忽略。
做爬虫请求网页时,要解析的内容就是响应体。
# 1.6 HTTP 2.0
HTTP 2.0 新增的一个强大功能是服务器可以对一个客户端请求发送多个响应。其他改进可查看相关文章。
# 2. Web 网页基础
<head> 标签定义了一些对页面的配置和引用,如 <meta charset="UTF-8"> 表示网页的编码是 UTF-8。
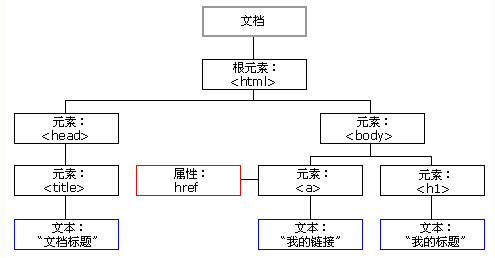
# 节点树
HTML DOM 将 HTML 文档视作树结构,这种结构被称为节点树:
# CSS 选择器
三种常见的 CSS 选择方式:
#container:选择 id 为 container 的标签;.wrapper:选择 class 为 wrapper 的标签;- 直接标签名
更多方式可见 [CSS 选择器参考手册](CSS 选择器参考手册 (w3school.com.cn) (opens new window))。
在浏览器中可以测试 CSS 选择器的效果,在开发者工具中的元素页面按下快捷键 Ctrl+F (Mac 中是 Command + F),会出现一个搜索框。
# 3. 爬虫基本原理
获取网页 => 提取信息 => 保存数据
# JS 渲染的页面
现在越来越多的网页采用 AJAX、前端模块化工具构建的,可能整个网页都是由 JS 渲染出来的,而原始的 HTML 代码就是一个空壳。在用 requests 等库请求当前页面时,我们得到的只是 HTML 代码,它不会继续加载 JS 文件,我们也就无法看到完整的页面内容。
对于这种情况,我们可以分析源代码的 AJAX 接口,也可以使用 Selenium、Splash、Pyppeteer、Playwright 等库来模拟 JS 渲染。
# 4. Session 和 Cookie
cookie 和 session 是什么 · 语雀 (opens new window)
# 5. 代理的基本原理
基本原理:代理实际上就是指代理服务器,英文叫作 Proxy Server,功能是伐网络用户取得网络信息。形象点说,代理是网络信息的中转站。当客户端正常请求一个网站时,是把请求发送给了 Web 服务器,Web 服务器再把响应传回给客户端。设置代理服务器,就是在客户端和服务器之间搭建一座桥,此时客户端并非直接向Web服务器发起请求,而是把请求发送给代理服务器,然后由代理服务器把请求发送给 Web 服务器,Web 服务器返回的响应也是由代理服务器转发给客户端的。这样客户端同样可以正常访问网页,而且这个过程中Web服务器识别出的真实IP就不再是客户端的 IP 了,成功实现了 IP 伪装,这就是代理的基本原理。
爬多了可能被封 IP,这时候就得加代理来解决。
高度匿名代理会将数据包原封不动地转发,在服务端看来似乎真的是一个普通客户端在访问,记录的 IP 也是代理服务器的 IP。
# 6. Python 的多线程和多进程
Python中 GIL 的限制导致不论是在单核还是多核条件下,同一时刻都只能运行一个线程,这使得 Python 多线程无法发挥多核并行的优势。GlL 全称为 Global Interpreter Lock,意思是全局解释器锁,其设计之初是出于对数据安全的考虑。
在Python多线程下,每个线程的执行方式分如下三步。
- 获取 GIL
- 执行对应线程的代码
- 释放 GIL
可见,某个线程要想执行,必须先拿到 GIL。我们可以把 GlL 看作通行证,并且在一个 Python 进程中,GL 只有一个。线程要是拿不到通行证,就不允许执行。这样会导致即使在多核条件下,一个 Python 进程中的多个线程在同一时刻也只能执行一个。
而对于多进程来说,每个进程都有属于自己的 GL,所以在多核处理器下,多进程的运行是不会受 GL 影响的。也就是说,多进程能够更好地发挥多核优势。
不过,对于爬虫这种密集型任务来说,多线程和多进程产生的影响差别并不大。但对于计算密集型任务来说,由于GIL的存在,Python 多线程的整体运行效率在多核情况下可能反而比单核更低。而 Python 的多进程相比多线程,运行效率在多核情况下比单核会有成倍提升。
从整体来看,Python的多进程比多线程更有优势。所以,如果条件允许的话,尽量用多进程。