 基本库的使用
基本库的使用
# 1. 正则表达式
正则表达式用于字符串的检索、替换和匹配。可以在 菜鸟正则表达式在线测试 (opens new window) 或 oschina正则表达式测试工具 (opens new window) 进行尝试。
Python 的 re 库提供了整个正则表达式的实现,往往选择使用它。第三方模块 regex (opens new window) , 提供了与标准库 re 模块兼容的 API 接口,同时,还提供了更多功能和更全面的 Unicode 支持。
# 1.1 match
re.match(pattern, string, flags=0)会尝试从字符串的起始位置开始匹配正则表达式,如果匹配,就返回一个相应的匹配对象 。 如果没有匹配,就返回
None;注意它跟零长度匹配是不同的。注意即便是
MULTILINE(opens new window) 多行模式, re.match() 也只匹配字符串的开始位置,而不匹配每行开始。
示例:
import re
content = 'Hello 123 4567 World_This is a Regex Demo'
pattern = '^Hello\s\d\d\d\s\d{4}\s\w{10}'
result = re.match(pattern, content)
print(result.group())
print(result.span())
2
3
4
5
6
7
输出:
Hello 123 4567 World_This
(0, 25)
2
group方法返回匹配的内容span方法返回匹配的范围
# 匹配目标
如果是想从字符串中提取一部分内容,比如从一段文本中提取出 email 地址,该怎么办?可以使用 () 将向提取的子字符串括起来。
示例:
import re
content = 'Hello 1234567 World_This is a Regex Demo'
pattern = '^Hello\s(\d+)\sWorld'
result = re.match(pattern, content)
print(result.group())
print(result.group(1))
2
3
4
5
6
7
输出:
Hello 1234567 World
1234567
2
可以看到 pattern 中数字部分的正则表达式被 () 括了起来,这样调用 group(1) 获取了匹配结果:
group()返回完整的匹配结果group(1)返回第一个被 () 包围的匹配结果
# 通用匹配
*代表匹配前面的字符无限次.代表可以匹配任意字符(除换行符)
# 贪婪与非贪婪
有时候通用匹配 .* 匹配到的内容不是我们想要的,这涉及到贪婪模式和非贪婪模式:
- 贪婪匹配是匹配尽可能多的字符
- 非贪婪匹配是匹配尽可能少的字符
示例,假如我们仍然向获得目标字符串中间的数字,所以正则表达式中间仍然写 (\d+),两边较为杂乱,所以用 .* 来匹配:
import re
content = 'Hello 1234567 World_This is a Regex Demo'
pattern1 = '^He.*(\d+).*Demo$' # 贪婪匹配
pattern2 = '^He.*?(\d+).*Demo$' # 非贪婪匹配
result1 = re.match(pattern1, content)
result2 = re.match(pattern2, content)
print(result1.group(1))
print(result1.group(1))
2
3
4
5
6
7
8
9
10
11
输出:
7
1234567
2
- 在贪婪匹配下,
.*会匹配尽可能多的字符,.*后面是\d+,也就是至少匹配一个数字,但没有规定几个数字,因此,.*会尽可能多的匹配,这里也就把 123456 都匹配了,只给\d+留下了一个可满足条件的数字 7 - 非贪婪匹配的写法是
.*?,也就是多了一个?,这里当.*?匹配到 Hello 后面的空白字符时,再往后就是数字了,可以交给(\d+)来匹配,于是.*?就不再匹配了,最终结果是(\d+)匹配了 1234567
所以说,在做匹配的时候、字符串中间尽量使用非贪梦匹配,也就是用 .*?代替 .*,以免出现匹配结果缺失的情况。
但这里需要注意,如果匹配的结果在字符串结尾,.*? 有可能匹配不到任何内容了,因为它会匹配尽可能少的字符。例如:
import re
content ='http://weibo.com/comment/kEraCN'
result1 = re.match('http.*?comment/(.*?)', content)
result2 = re.match('http.*?comment/(.*)', content)
print('result1',result1.group(1))
print('result2',result2.group(1))
2
3
4
5
6
运行结果如下:
result1
result2 kEraCN
2
可以观察到,.*?没有匹配到任何结果,而 .* 则是尽量多匹配内容,成功得到了匹配结果。
# 修饰符(标记)
正则表达式的标记用于指定额外的匹配策略。
标记不写在正则表达式里,标记位于表达式之外,格式如下:
/pattern/flags
下表列出了正则表达式常用的修饰符:
| 修饰符 | 含义 | 描述 |
|---|---|---|
| i | ignore - 不区分大小写 | 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别。 |
| g | global - 全局匹配 | 查找所有的匹配项。 |
| m | multi line - 多行匹配 | 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾。 |
| s | 特殊字符圆点 . 中包含换行符 \n | 默认情况下的圆点 . 是 匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。 |
- 在
re库中,是写在 match 方法的第三个参数里,比如re.match(p, s, re.S) - 较为常用的是 re.S 和 re.I
Python 示例:
import re
content = """Hello 1234567 World_This
is a Regex Demo
"""
pattern = '^He.*?(\d+).*Demo$'
result1 = re.match(pattern, content)
print(result1.group(1))
2
3
4
5
6
7
8
9
运行后会报错,因为未匹配成功导致 match 返回一个 None,在 None 上调用 group 引发错误。这里 .* 无法匹配换行符,我们再加一个修饰符 re.S 便可以得到解决:
result2 = re.match(pattern, content, re.S)
print(result2.group(1))
2
这个 re.S 在网页匹配中经常用到,因为 HTML 节点经常会有换行,加上他,就可以匹配节点与节点之间的换行了。
# 转义匹配
当在目标字符串中遇到用作正则匹配模式的特殊字符时,在此字符前面加上反斜线 \ 转义一下即可。比如 \. 可以匹配 .。
# 1.2 search 和 findall
match 是从字符串的开头开始匹配的,意味着一旦开头不匹配,整个匹配就失败了。
- search 会在匹配时扫描整个字符串,然后返回第一个匹配成功的结果,如果扫描完都没有找到,那返回 None
- findall 获取与正则表达式相匹配的所有字符串,其返回结果是列表类型
如果只想获取匹配的第一个字符串,可以用 search 方法,如果需要提取多个内容,可以用 findall 方法。
# 1.3 sub
除了使用正则表达式提取信息,有时候还需要借助它来修改文本。例如,想要把一串文本中的所有数字都去掉,如果只用字符串的 replace 方法,未免太烦琐了,这时可以借助 sub 方法。实例如下:
import re
content = '54aK54yr50iR54ix5L2g'
content = re.sub('\d+', '', content)
print(content)
2
3
4
运行结果如下:
aKyroiRixLg
这里往 sub 方法的第一个参数中传人 \d+ 以匹配所有的数字,往第二个参数中传入把数字替换成的字符串(如果去掉该参数,可以赋值为空),第三个参数是原字符串。
# 1.4 compile
compile 方法可以将正则字符串编译成正则表达式对象,以便在后面的匹配中复用。另外,compile 还可以传入修饰符,例如 re.S 等修饰符,这样在 search、findall 等方法中就不用额外传递了。
import re
content1 = '2019-12-15 12:00'
content2 = '2020-06-12 13:15'
content3 = '2021-09-01 14:20'
pattern = re.compile('\d{2}:\d{2}')
result1 = re.sub(pattern, '', content1)
result2 = re.sub(pattern, '', content2)
result3 = re.sub(pattern, '', content3)
print(result1, result2, result3)
2
3
4
5
6
7
8
9
10
11
12
13
输出:
2019-12-15 2020-06-12 2021-09-01
更多方法可以参见 Python3 正则表达式 | 菜鸟教程 (runoob.com) (opens new window) 或官方文档 re --- 正则表达式操作 (opens new window)
# 2. httpx 的使用
有些网站强制使用 HTTP/2.0 协议访问,而 urilib 和 requests 只支持 HTTP/1.1,这时可以采用 hyper 或 httpx,后者使用更方便,功能更强大。
# 案例
https://spa16.scrape.center/ 就是一个强制使用 HTTP/2.0 访问的网站,用浏览器打开后查看 Network 可以看到传输全部是通过 h2 方式。
如果我们使用 requests 爬取,会产生错误:
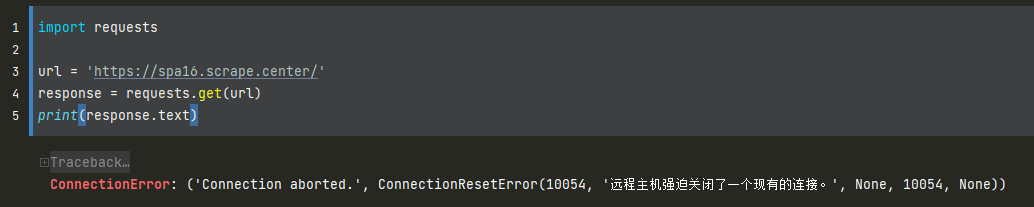
# 安装
见官方文档
# 基本使用
用 httpx 来爬取刚刚的网站:
import httpx
url = 'https://spa16.scrape.center/'
client = httpx.Client(http2=True)
response = client.get(url)
print(response.text)
2
3
4
5
6
- 注意默认不会开启对 HTTP/2.0 的支持,需要手动声明。
注意在客户端的 httpx 上启用对HTTP/2.0的支持并不意味着请求和响应都将通过 HTTP/2.0 传输,这得客户端和服务端都支持 HTTP/2.0 才行。如果客户端连接到仅支持 HTTP/1.1 的服务器,那么它也需要改用HTTP/1.1。
其他用法见官网。
# 3. XPath 的使用
XPath,即 XML 路径语言,是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
# 3.1 XPath 常用规则
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
- 具体示例可见下面
# 3.2 实例引入
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
result = etree.tostring(html) # 此时 result 是 bytes 类型
print(result.decode('utf-8'))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
在 etree.HTML(text) 中,这一步会自动修正 text 所表示的 HTML 文本,转换成 str 后打印结果为:
<html><body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul>
</div>
</body></html>
2
3
4
5
6
7
8
9
10
11
- 可见原先
text中未闭合的li节点被补全了,并自动添加了 body、html 节点
另外也可以直接读取文本文件进行解析:html = etree.parse('./text.html', etree.HTMLParser())。
# 3.3 所有节点
一般会用以 // 开头的 XPath 规则来选取所有符合要求的节点。
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//*')
print(result)
2
3
4
- 这里
*达标匹配所有节点,运行结果是一个 Element 元素的列表。
# 3.4 子节点
/获取直接子节点。比如//li/a获取 li 节点的所有直接子节点 a。//获取子孙节点。比如//ul//a获取 ul 节点下的所有子孙节点 a。
# 3.5 文本获取
/text()获取当前节点的内部文本,注意,如果<li>first<a>second</a></li>,这样/li/text()获取的是 first 而不包含 second//text()获取所有子孙节点的文本,比如上面的/li//text()则会获取到 first 和 second。
示例:
from lxml import etree
text = '<li>first<a>second</a></li>'
html = etree.HTML(text)
result1 = html.xpath('//li/text()')
print(result1)
result2 = html.xpath('//li//text()')
print(result2)
2
3
4
5
6
7
8
输出结果:
['first']
['first', 'second']
2
# 3.6 属性匹配和属性获取
- 属性匹配——
[@class=‘item-0’]限制所选取的节点的 class 属性必须为 item-0 - 属性获取——
@href表示获取节点的 href 属性
示例:
result1 = html.xpath('//li[@class="item-0"]') # 属性匹配
result2 = html.xpath('//li/a/@href') # 属性获取
2
# 属性多值匹配
有时候,某些节点的某个属性可能有多个值:
from lxml import etree
text = '''
<li class="li li-first"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[@class="li"]/a/text()')
print(result)
2
3
4
5
6
7
这里 li 节点的 class 属性有两个值:li 和 li-first,此时如果还用之前的属性匹配获取节点,就无法进行了,这时需要用到 contains 方法,需要修改为:
from lxml import etree
text = '''
<li class="li li-first"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class, "li")]/a/text()')
print(result)
2
3
4
5
6
7
- contains 方法,第一个参数为属性名称,第二个是属性值,只要传入的属性包含传入的属性值,就可以完成匹配。
# 多属性匹配
还有一种情况是根据多个属性来确定一个节点,这时需要同时匹配多个属性。运算符 and 用于连接多个属性:
from lxml import etree
text = '''
<li class="li li-first" name="item"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class, "li") and @name="item"]/a/text()')
print(result)
2
3
4
5
6
7
除此之外,还有很多其他运算符:
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有 book 和 cd 元素的节点集 |
| + | 加法 | 6 + 4 | 10 |
| - | 减法 | 6 - 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true。如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true。如果 price 是 9.50,则返回 false。 |
| and | 与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true。如果 price 是 8.50,则返回 false。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
# 3.7 按序选择
选择节点时,可能匹配了多个节点,但我们只想要其中第一个或最后一个,怎么办?
可以使用向中括号传入索引的方法获取特定次序的节点,但要注意,xpath 里面与写代码不同,序号是以 1 开头,而不是 0。
示例:
//li[1]表示选取第一个 li 节点;//li[last()]表示选取最后一个 li 节点;//li[position()<3]表示选取位置小于 3 的 li 节点,即序号 1 和 2 的节点;//li[last()-2]表示选取了倒数第三个节点,因为 last() 代表最后一个,再减 2 就是倒数第三个了。
# 3.8 节点轴选择
轴可定义相对于当前节点的节点集。
| 轴名称 | 结果 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点。 |
示例:
from lxml import etree
text = '''
<html><body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul>
</div>
</body></html>
'''
html = etree.HTML(text)
result = html.xpath('//li[1]/ancestor::*') # 获取第一个 li 节点的所有祖先节点
print(result) # 包括 html、body、div 和 ul
result = html.xpath('//li[1]/ancestor::div')
print(result)
result = html.xpath('//li[1]/attribute::*') # 第一个 li 节点的所有属性值
print(result)
result = html.xpath('//li[1]/child::a[@href="link1.html"]') # 所有直接子节点中的符合属性条件的 a 节点
print(result)
result = html.xpath('//li[1]/descendant::span') # 所有子孙节点中的 span 节点
print(result)
result = html.xpath('//li[1]/following::*[2]') # 当前节点之后的第二个节点
print(result)
result = html.xpath('//li[1]/following-sibling::*') # 所有的后续同级节点
print(result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 4. pyquery 的使用
占坑...
# 5. parsel 的使用
parsel 这个库可以解析 HTML 和 XML,并同时支持使用 XPath 和 CSS 选择器对内容进行提取和修改同时还融合了正则表达式的提取功能。parsel 灵活且强大,同时也是 Python 最流行的爬虫框架 Scrapy 的底层支持。