 JavaScript 动态渲染页面爬取
JavaScript 动态渲染页面爬取
有时候我们用 requests 得到的页面和我们在浏览器中所看到的不一样,这是因为 requests 获取的都是原始的 HTML 文档,而浏览器中的页面是 JavaScript 处理数据之后生成的结果,这些数据有多种来源,可能是通过 Ajax 加载的,也可能是包含在 HTML 文档中的,还可能是经过 JS 和特定算法生成的。
# 1. Ajax
当页面数据是通过 Ajax 请求获得的时候,需要分析请求接口,并对请求接口进行抓取来获得数据。
# 1.1 什么是 Ajax
Ajax 允许通过与场景后面的 Web 服务器交换数据来异步更新网页。这意味着可以更新网页的部分,而不需要重新加载整个页面。
以微博 https://m.weibo.cn/u/2830678474 为例,可以一直下滑查看更多微博,但始终未发生页面 URL 的变化,这后面刷新出来的数据就是 Ajax 请求得到的。
# 基本原理
JavaScript 实现 Ajax 请求的代码如下:
var xhttp;
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else {
// code for IE6, IE5
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
document.getElementById("demo").innerHTML = this.responseText;
}
};
xhttp.open("GET", "/test-api", true);
xhttp.send();
2
3
4
5
6
7
8
9
10
11
12
13
14
- 整个过程就是先新建一个 XMLHttpRequest 对象 xhttp,然后调用 onreadystatechange 属性设置监听,最后调用 open 和 send 方法向某个连接发送请求。
真实的网页数据其实就是一次次向服务器发送 Ajax 请求得到的,要想抓取这些数据,需要知道 Ajax 请求到底是怎么发送的、发往哪里、发了哪些参数。我们知道了这些信息后,便可以用 Python 来模拟发送请求来获取数据。
# 1.2 Ajax 分析方法
仍然以 https://m.weibo.cn/u/2830678474 为例,打开页面后在浏览器中打开开发者工具的 Network 部分,可以看到所有网络请求。Ajax 有其特殊的请求类型,叫做 xhr,也可以利用筛选功能筛选出 XHR 的请求:
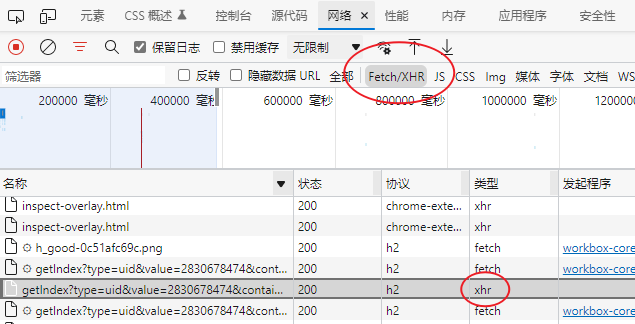
点击该请求可以看到详细信息,其中在 Request Headers 中有一个信息为 X-Requested-With: XMLHttpRequest,这就标记了此请求是 Ajax 请求。
随后单击一下 Preview 或者 Response 选项卡就可以看到返回的数据。
# 2. Selenium 的使用
# 3. Pyppeteer
# 4. Playwright 的使用
Playwright 是微软在 2020 年初开源的新一代自动化测试工具,它的功能类似于 Selenium、Pyppeteer 等,都可以驱动浏览器进行各种自动化操作。它的功能也非常强大,对市面上的主流浏览器都提供了支持,API 功能简洁又强大。虽然诞生比较晚,但是现在发展得非常火热。
# 4.1 特点
- Playwright 支持当前所有主流浏览器,包括 Chrome 和 Edge(基于 Chromium)、Firefox、Safari(基于 WebKit) ,提供完善的自动化控制的 API。
- Playwright 支持移动端页面测试,使用设备模拟技术可以使我们在移动 Web 浏览器中测试响应式 Web 应用程序。
- Playwright 支持所有浏览器的 Headless 模式和非 Headless 模式的测试。
- Playwright 的安装和配置非常简单,安装过程中会自动安装对应的浏览器和驱动,不需要额外配置 WebDriver 等。
- Playwright 提供了自动等待相关的 API,当页面加载的时候会自动等待对应的节点加载,大大简化了 API 编写复杂度。
# 4.2 安装
Playwright-python 的安装
pip install playwright -i https://mirrors.aliyun.com/pypi/simple/ 使用阿里源,下载速度快一点。
python -m playwright install 安装chromium、frefox、webkit (opens new window)。
使用时用 python -m playwright [commands] 即可。