 语义Web程序设计简介
语义Web程序设计简介
# chapter 1 语义Web程序设计基础
语义 Web 并不是一个单独的 Web,而是当前 Web 的扩展,语义 Web 上的信息被赋予了正确定义的含义,从而使计算机和人能够更好地协作。
—— Tim Berners-Lee
我们所关注的两个关键领域:语义 Web 和 语义 Web 上的程序设计。
# 1.1 定义语义 Web
语义通过确定关键字符号之间的关系来为关键字赋予有用的含义,如“building”和其他关键字“建筑师”、“工地”等相关联能够揭示一定的语义关系。
简单来说,语义 Web就是一个数据网,这些数据以多种方式进行描述,相互链接形成上下文(或者说语义关系),而这种上下文遵从规定的语法和语言构造。
语义 Web 的基本构成单元是陈述(Statement),即三元组。这些陈述使用了相同的标准,以便于利用语义进行共享和集成。可以说语义关系构成了语义 Web,通过图可以很形象地表示一个陈述集合(如上图)。定义了概念与概念之间关系的这些陈述构成了一个本体,针对实例个人的陈述则形成了实例数据。可以对陈述进行声明和推理,声明需要由应用程序直接创建陈述,而推理需要借助推理机从逻辑上对其他陈述进行推理得到。
存储方式:在语义 Web 上发挥作用的陈述集合主要表现为两种形式:知识库和文件。知识库提供了对陈述的动态可扩展的存储,而文件则一般存储静态的陈述。
对比关系型数据库:关系数据库在结构上依赖于模式;知识库则依赖本体陈述来确立结构。关系数据库只有一种关系,即外键;而语义Web则提供了多维度的关系,如继承关系、part of关系、关联关系和其他多种类型的关系,这其中还包括逻辑关系和约束。需要重点关注的是,在知识库中构成结构和实例本身的是同一种语言,而在数据库中则是完全不同的。关系数据库是通过数据描述语言(DDL)来支持模式的创建的。在关系数据库中,添加一个表或者列和添加一个行是完全不同的。而知识库则与之不同,因为定义知识库结构(或模式)的陈述和定义个体(或实例)的陈述都是一样的。这种做法具有很多优点,我们将在后续的章节中逐步探究。
| 特性 | 关系型数据库 | 知识库 |
|---|---|---|
| 结构 | 模式 | 本体陈述 |
| 数据 | 行 | 实例陈述 |
| 管理语言 | DDL | 本体陈述 |
| 查询语言 | SQL | SPARQL |
| 关系 | 外键 | 多个维度的关系 |
| 逻辑 | 数据库外部/触发器 | 形式化的逻辑陈述 |
| 唯一性 | 键 | URI |
# 1.2 语义 Web 的主要组件
这些组件主要分为两类:语义 Web 的主要组件和相关的工具。
核心组件包括:陈述、统一资源标识符(URI)、语义 Web 语言、本体和实例数据:
- 陈述:每个陈述形成一个SPO三元组,包括主语(subject)、谓语(predicate)和宾语(object),例如
John isType Person。陈述定义了信息结构、具体实例和对这种结构的限定条件,他们的相互关联形成了数据网络,也就构成了语义 Web。 - URI:统一资源标识符,为陈述中所包含的术语提供了一个在整个 Internet 上都唯一的名称。这种做法消除了命名冲突。
- 语言:陈述是按照语义 Web 语言表达的。语言由一个关键字集合组成,他们为 Web 工具提供了指令。
- 本体:由定义概念、关系和约束的陈述所组成。本体和数据库模式以及面向对象程序中的类图十分相似,构成了一个信息领域模型。目前已经存在很多富语义的本体,语义 Web 程序最好能够利用这些已有的各种领域本体,并针对具体问题域来添加自己的陈述来构成本体。
- 实例数据:也是一种陈述,含有与具体实例相关的信息,而不是关于一般概念的信息。比如 John 是一个实例,而 person 是一个概念(类)。
相关工具包含:建造工具、询问工具、推理机、规则引擎和语义框架等:
- 建造工具:比如语义 Web 编辑器,可以使你的应用程序构建并集成到语义 Web,具体是通过在本体和实例上创建或者通过导入陈述来实现。
- 询问工具:通过语义 Web 进行导航,返回所请求的应答。
- 推理机:为语义 Web 加入了推理功能。推理能够提供分类和辨识等逻辑附加功能。分类可以对类结构进行填充,使得概念和关系能够正确地关联,比如 person 是一个 living-thing,father 是一个 parent,那么可以推理出 father 也是 living-thing。辨识也类似,可以通过推理得知实例 John 和实例 J H 是相同。推理机通常嵌入到其他工具中使用,利用已经声明的陈述创建出逻辑上合法的附属陈述。
- 规则引擎:能够支持超出描述逻辑演绎能力的推理功能。
- 语义框架:语义框架是将上面所列举的各种工具打包到一起形成一个集成单元。
这些概念的关系:陈述、URI、语言、本体和实例数据组成了语义 Web,形成了相互关联的语义信息。语义工具创建、操作、询问和充实了语义 Web。
# 1.3 语义 Web 技术对程序设计的影响
程序设计必须充分利用语义 Web 的技术及相关工具,适应语义 Web 技术的预期及影响,将影响可以分为四大类:
# (1)以 Web 数据为中心
大多数程序重点关注程序设计指令,而语义Web程序则以数据为中心,数据的充实有助于减轻程序设计的负担。视角应当从原来小规模、孤立的、以程序为中心的视角提升到全球性的、相互依存的、以 Web 为中心的视角。
# (2)表达语义数据
语义 Web 应用程序应当直接将含义置于数据中,通过将各种概念关联到一起,改良了语义,构建出一个可供应用程序广泛使用的上下文环境。
关系的继承性
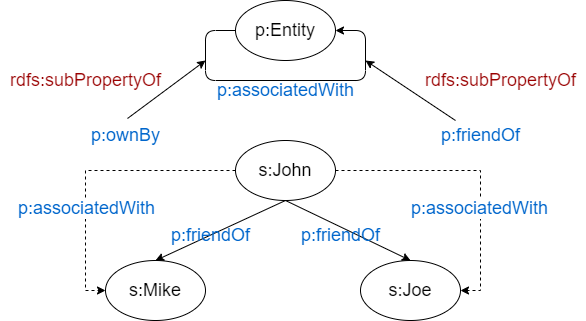
关系具有继承性和约束规则,以下面为例,一个社会网络关系应当提供 associatedWith 关系,该关系包含了一个子关系 ownBy 和另一个子关系 friendOf:
上面是本体,下面是实例数据,如果继承了 associatedWith 关系,应用程序就可以查询到所有具有 associatedWith 关系的数据,在本例中也包括 Tom 和 OldCar。
语义 Web 为实例提供了一定的灵活性,一个实例并非永远绑定到某个类或类的集合,一个实例也可以根本就没有类,而仅仅作为一个实例陈述,或者也可以和多个类相关联。您的应用程序应当可以动态地改变实例和类之间的关联。
# (3)共享数据
信息交换的能力增加了数据的价值。大型数据集成面临着数据冲突和数据故障的重大挑战。
数据冲突源于数据无法对准,比如 Oracle 数据库中有一个 Person 的表,而 MySQL 中有一个 Individual 的表,这两者从不同的视角来描述自己的问题,但若要把他们集成起来就会产生冲突。语义 Web 的陈述通过将相似的概念关联起来,从而减少冲突。
数据故障是由于缺失数据、冲突数据和不正确数据所造成的。语义 Web 的灵活性使得数据的集成与修改过程能够连续地进行修正。
命名也是共享信息的一大挑战。语义 Web 上各种产物本质上在整个万维网范围内都是唯一的。
和其他方法相比,计算机可读性、数据冲突和数据故障的管理,以及唯一的、可解析的名称都为大规模的数据集成和共享铺平了道路。
# (4)使数据动态而灵活
设计良好的语义 Web 应用程序允许随时加入新数据,这使得其能够正确地与当前需求相对准。语义 Web 通过对信息进行推理可以得到新的结论,推理机也能够找出你的信息中存在的逻辑矛盾。推理过程也容易产生“输入的是垃圾,输出的也是垃圾”的现象。
推理举例
假设你的信息包含下面的事实:John 是一位男性,男性是人的一种类型,则系统就能够推理出 John 是一个人。因此当查询请求所有的人时,系统会返回 John。
语义 Web 使得各个相关的信息小块之间建立了富有意义的链接,从而提供了一种新的信息导航的形式。你可以从 语义Web上某一点出发,通过特定的关系集合来进行探索。
语义 Web 是动态的。可以随时添加信息,概念也可以随时进行演化从而变得更加有用和准确。
语义 Web 具有很强的包容性。能够灵活地表达信息,这使得它能够统一和充实其他数据源和服务。
# 1.4 语义 Web 的示例
# (1)语义 Wiki
semantic-mediawiki.org
# (2)FOAF 项目
www.foaf-project.org
该项目提供了一些工具来建立人们之间的关联。它有一个供多个应用程序使用的本体。
# (3)RDFa 和微格式
这种格式直接将语义嵌入到一个典型的 XHTML 网页中。Firefox 的扩展插件——Semantic Radar 能够检查网页的语义内容。
# (4)语义查询端点
dbpedia.org/sparql
语义查询端点提供了最终的信息公开,即能够针对使用标准语义查询语言 SPARQL 构成的提问给出应答的一些 URL。
# chapter 2 语义网编程示例
现在假设有一个人叫做“Semantic Web”,我们要向他和他的朋友发出“Hello”的问候。这个示例是对大部分内容的一个概览,涵盖 Jena、SPARQL、Protege 的使用以及本体融合、语义推理等内容。
# 2.1 开发环境
- Java 1.6
- IDE:IDEA(推荐) 或 Eclipse
- 本体编辑工具:Protege
- 语义 Web 程序设计框架:Jena 2.5.6
- 本体推理机:Pellet 1.5.2
使用 IDEA 打开 chapter2 中的 HelloSemanticWeb 项目,在 Project Structure 中导入库 jena/lib 下的 jar 和 pellet.jar,使用 Java 1.6 环境,即可成功运行程序。
# 2.2 编写 HelloSemanticWeb 程序
# TASK 1 向 Semantic Web 先生及其朋友问好
首先创建实例数据:FOAF-a-Matic (opens new window) 提供了一种填表的形式来生成有关人们及其社会交往信息的语义 Web 实例数据。我们为一个虚拟的人“SemanticWeb 先生”填充了一个 FOAF 图,并用 Turtle 格式对齐保存并分析。
<people:me> rdf:type foaf:Person ;
foaf:depiction <http://semwebprogramming.org/semweb.jpg> ;
foaf:family_name "Web" ;
foaf:givenname "Semantic" ;
foaf:homepage <http://semwebprogramming.org> ;
foaf:knows <swp2:Ontology>,
<swp2:Reasoner>,
<swp2:Statement> ;
foaf:name "Semantic Web" ;
foaf:nick "Webby" ;
foaf:phone <tel:410-679-8999> ;
foaf:schoolHomepage <http://www.web.edu> ;
foaf:title "Dr" ;
foaf:workInfoHomepage <http://semwebprogramming.com/dataweb.html> ;
foaf:workplaceHomepage <http://semwebprogramming.com> .
<people:Ontology> rdf:type foaf:Person ;
rdfs:seeAlso <http://ont.com> ;
foaf:mbox <mailto:ont@gmail.com> ;
foaf:name "I. M. Ontology" .
<people:Reasoner> rdf:type foaf:Person ;
rdfs:seeAlso <http://reasoner.com> ;
foaf:mbox <mailto:reason@firefox.com> ;
foaf:name "Ican Reason" .
<people:Statement> rdf:type foaf:Person ;
rdfs:seeAlso <http://statement.com> ;
foaf:mbox <mailto:mstatement@gmail.com> ;
foaf:name "Makea Statement" .
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
我们将 http://org.semwebprogramming/chapter2/people# 作为我们这个项目中自定义的前缀,并以 people: 来简写。第一组陈述描述了 <people:me> ,这个便是“Semantic Web 先生”,我们可以看到他认识(由 foaf:knows 指示)其余三个人,这三人由下面的三组陈述来描述,将我们目前的关注点绘制一张图便是如下:
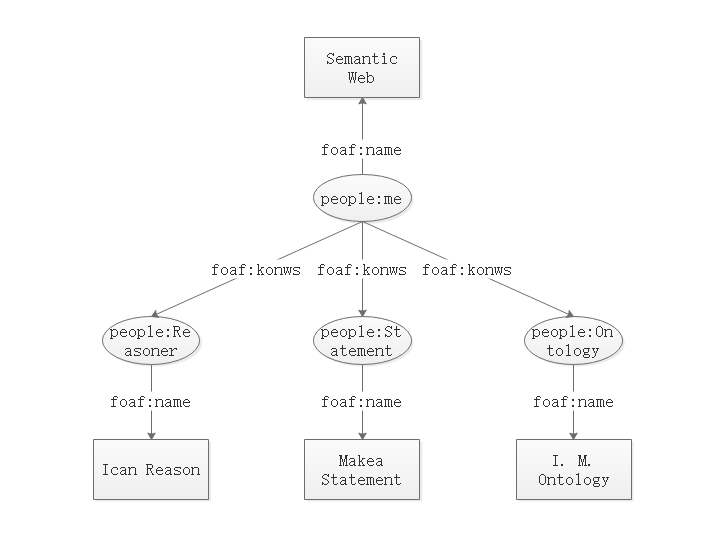
Jena 框架抽象出一种数据结构 Model 来存储各种陈述 Statement,所以我们接下来要做的是把数据载入 model 中:
public class HelloSemanticWeb {
static String defaultNameSpace = "http://org.semwebprogramming/chapter2/people#";
Model _friends = null;
Model schema = null;
InfModel inferredFriends = null;
public static void main(String[] args) throws IOException {
HelloSemanticWeb hello = new HelloSemanticWeb();
// Load my FOAF friends
System.out.println("Load my FOAF Friends");
hello.populateFOAFFriends();
....
}
private void populateFOAFFriends(){
_friends = ModelFactory.createOntologyModel();
InputStream inFoafInstance = FileManager.get().open("Ontologies/FOAFFriends.rdf");
_friends.read(inFoafInstance,defaultNameSpace);
//inFoafInstance.close();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
_friends模型装载了我们的实例数据
接下来向 Semantic Web 先生问好:
我们先将对model中的数据查询编写一个工具函数,以方便完成本次及以后的任务:
private void runQuery(String queryRequest, Model model){
StringBuffer queryStr = new StringBuffer();
// Establish Prefixes
//Set default Name space first
queryStr.append("PREFIX people" + ": <" + defaultNameSpace + "> ");
queryStr.append("PREFIX rdfs" + ": <" + "http://www.w3.org/2000/01/rdf-schema#" + "> ");
queryStr.append("PREFIX rdf" + ": <" + "http://www.w3.org/1999/02/22-rdf-syntax-ns#" + "> ");
queryStr.append("PREFIX foaf" + ": <" + "http://xmlns.com/foaf/0.1/" + "> ");
//Now add query
queryStr.append(queryRequest);
Query query = QueryFactory.create(queryStr.toString());
QueryExecution qexec = QueryExecutionFactory.create(query, model);
try {
ResultSet response = qexec.execSelect();
while( response.hasNext()){
QuerySolution soln = response.nextSolution();
RDFNode name = soln.get("?name");
if (name != null) {
System.out.println( "Hello to " + name.toString() );
}
else
System.out.println("No Friends found!");
}
} finally { qexec.close();}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
runQuery接收一个 SPARQL 的查询语句queryRequest,对model进行查询。它首先将所有要用到的 prefix 附加到查询语句前面,构成一个有效的 SPARQL 语句,然后运行查询任务,并对查出的所有 name 打印出一个问候消息。QueryExecutionFactory用来创建查询;execSelect用来执行查询。
有了runQuery函数,我们要想对 Semantic Web 先生问好,只需要写出一个将 Semantic Web 先生查询出来的 SPARQL 语句,实现如下:
private void mySelf(Model model){
// Hello to Me
runQuery(" select DISTINCT ?name where{ people:me foaf:name ?name }", model);
}
2
3
4
运行后可以看到输出:
Say Hello to Myself
Hello to Semantic Web
2
按照上面的思路,向其朋友问好也就只需要换一下查询的 SPARQL 语句即可:
private void myFriends(Model model){
// Hello to just my friends - navigation
runQuery(" select DISTINCT ?myname ?name where{ people:me foaf:knows ?friend. ?friend foaf:name ?name } ", model);
}
2
3
4
运行后可以看到输出:
Say Hello to my FOAF Friends
Hello to I. M. Ontology
Hello to Ican Reason
Hello to Makea Statement
2
3
4
# TASK 2 扩展朋友列表,融合两个不同的数据源,并向所有朋友问好
我们之前使用了一个数据源,现在我们准备将两个不同的数据源融合起来。现在问题是新的数据源是基于一个完全不同的视角来看待这个世界,他们使用的词汇集是不同的,比如同样表达“人”这个概念,原有的数据集使用 Person,而新的数据集使用 Indivudual,这就需要本体对齐工作。
之前的数据源可以使用 FOAF 这个公开本体,存在于 foaf.rdf 这个文件中。我们接下来要使用 Protege 创建一个新的数据源。Protege 可以用来创建本体(类、类的继承关系等)和实例,利用本体可以确定语义关系。
使用 Protege 创建本体:在 owl:Thing 下面创建类 Individual :
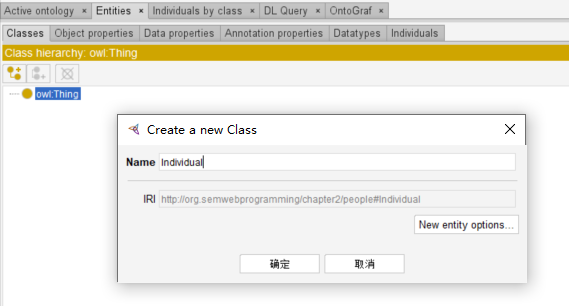
再添加 Object Property people:hasFriend 和 Data Property people:hasName :
- Object Property 是指它将两个资源(或叫作个体)关联了起来,Data Property 是指它将一个资源和文字关联了起来。
现在,我们有了一个拥有类和关系的本体,保存本体到 additionalFriendsSchema.owl 中:
@prefix : <http://org.semwebprogramming/chapter2/people#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
<http://org.semwebprogramming/chapter2/people> rdf:type owl:Ontology .
:Individual rdf:type owl:Class .
:hasName rdf:type owl:DatatypeProperty .
:hasFriend rdf:type owl:ObjectProperty,
owl:SymmetricProperty ;
owl:inverseOf :hasFriend .
2
3
4
5
6
7
8
9
10
11
12
于是我们可以将这个本体与之前的 FOAF 本体载入程序中:
private void populateFOAFSchema() throws IOException{
InputStream inFoaf = FileManager.get().open("Ontologies/foaf.rdf");
InputStream inFoaf2 = FileManager.get().open("Ontologies/foaf.rdf");
schema = ModelFactory.createOntologyModel();
//schema.read("http://xmlns.com/foaf/spec/index.rdf");
//_friends.read("http://xmlns.com/foaf/spec/index.rdf");
// Use local copy for demos without network connection
schema.read(inFoaf, defaultNameSpace);
_friends.read(inFoaf2, defaultNameSpace);
inFoaf.close();
inFoaf2.close();
}
private void populateNewFriendsSchema() throws IOException {
InputStream inFoafInstance = FileManager.get().open("Ontologies/additionalFriendsSchema.owl");
_friends.read(inFoafInstance,defaultNameSpace);
inFoafInstance.close();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
使用 Protege 创建实例:在实例页面添加如下三个实例和他们的属性
@prefix : <http://org.semwebprogramming/chapter2/people#> .
:Individual_5 rdf:type :Individual ;
:hasFriend :Individual_6,
:Individual_7 ;
:hasName "Sem Web" .
:Individual_6 rdf:type :Individual ;
:hasFriend :Individual_5 ;
:hasName "Web O. Data" .
:Individual_7 rdf:type :Individual ;
:hasFriend :Individual_5 ;
:hasName "Mr. Owl" .
2
3
4
5
6
7
8
9
10
11
12
13
14
这里的Individual_5也是指代的“Semantic Web 先生”,虽然语义与以前相同,但词汇集上有了差别,这种差别导致原来的程序无法找到这里所描述的朋友。
我们先将这些实例数据载入程序:
private void populateNewFriends() throws IOException {
InputStream inFoafInstance = FileManager.get().open("Ontologies/additionalFriends.owl");
_friends.read(inFoafInstance,defaultNameSpace);
inFoafInstance.close();
}
2
3
4
5
为了将 foaf:Person 和 people:Individual 这两个名称对齐,我们需要将它们的语义对齐,即使它们在语法上存在差别,但我们可以在语义上使他们等价。首先,我们需要一个这样的模型:该模型桥接了两个本体的关键部分,从而使得我们的查询能够涵盖所有朋友。这就是本体对齐。经分析,我们所要做的工作如下:
- people:Individual 等价于 foaf:Person 【用 owl:equivalentClass】
- people:hasName 等价于 foaf:name【用 owl:equivalentProperty】
- people:hasFriend 是 foaf:knows 的子属性【用 rdfs:subPropertyOf】
- people:me 等价于 peopke:Individual_5【用 owl:sameAs】
我们有两个选择:声明参与比较的一对元素完全等价或者声明一个元素为另一个元素的特化。可以通过编程的方式添加陈述,也可以用 Protege 来创建这样的陈述并读入。我们选择前者,代码为:
private void addAlignment(){
// State that :individual is equivalentClass of foaf:Person
Resource resource = schema.createResource(defaultNameSpace + "Individual");
Property prop = schema.createProperty("http://www.w3.org/2002/07/owl#equivalentClass");
Resource obj = schema.createResource("http://xmlns.com/foaf/0.1/Person");
schema.add(resource,prop,obj);
//State that :hasName is an equivalentProperty of foaf:name
resource = schema.createResource(defaultNameSpace + "hasName");
//prop = schema.createProperty("http://www.w3.org/2000/01/rdf-schema#subPropertyOf");
prop = schema.createProperty("http://www.w3.org/2002/07/owl#equivalentProperty");
obj = schema.createResource("http://xmlns.com/foaf/0.1/name");
schema.add(resource,prop,obj);
//State that :hasFriend is a subproperty of foaf:knows
resource = schema.createResource(defaultNameSpace + "hasFriend");
prop = schema.createProperty("http://www.w3.org/2000/01/rdf-schema#subPropertyOf");
obj = schema.createResource("http://xmlns.com/foaf/0.1/knows");
schema.add(resource,prop,obj);
//State that sem web is the same person as Semantic Web
resource = schema.createResource("http://org.semwebprogramming/chapter2/people#me");
prop = schema.createProperty("http://www.w3.org/2002/07/owl#sameAs");
obj = schema.createResource("http://org.semwebprogramming/chapter2/people#Individual_5");
schema.add(resource,prop,obj);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
提示
注意区分 owl:sameAs 和 owl:equivalentClass,前者用于等价实例,后者用于等价类。
添加以上陈述后可以得到如下的图,可以看到两个本体的语义关联了起来。
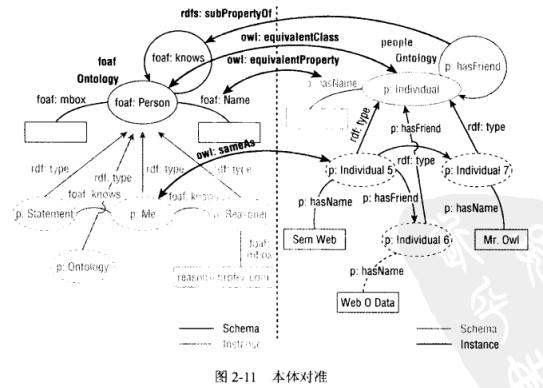
但是,这些陈述仅仅将本体相互关联了起来,并没有将朋友实例进行关联,比如说 Ican Reason 仍然是一个 foaf:Person 而不是 people:Individual,所以我们现在的查询仍然不能向任何一个朋友问好,解决方案就是推理。
像 Jena 中包含的推理机支持附加的可推断陈述或蕴含。事实上,Jena 有多个推理机,也具有支持外部第三方推理机的接口。我们现在使用Jena默认的 OWL 推理机。推理机基于其推理能力来检查本体陈述,并添加可用于推断的陈述。下面的代码介绍了获取 Jena 推理机并且将其绑定到 model 的方法:
private void bindReasoner(){
Reasoner reasoner = ReasonerRegistry.getOWLReasoner();
reasoner = reasoner.bindSchema(schema);
inferredFriends = ModelFactory.createInfModel(reasoner, _friends);
}
2
3
4
5
这样便获得了一个 inferredFirends 模型,并将其与一个基于 _friends 模型的推理机绑定。这个扩展的 model 既包括我们添加的陈述,也包括所有从后续添加的陈述中推导出来的蕴含。
也可以试着尝试使用外部的 Pellet 推理机来代替 Jena 内置的推理机:
private void runPellet( ){
Reasoner reasoner = PelletReasonerFactory.theInstance().create();
reasoner = reasoner.bindSchema(schema);
inferredFriends = ModelFactory.createInfModel(reasoner, _friends);
}
2
3
4
5
到此为止,我们做好了准备,再次调用之前的向朋友问候的函数:
hello.myFriends(hello.inferredFriends);
- 调用的函数一样,只是参数由以前的
_friends改成了经过推理的inferredFriends。可以发现,经过本体对立和推理,我们可以不经修改 SPARQL 查询语句便实现对使用了不同词汇集的不同数据源进行统一的查询。
运行结果中可以看到包含了新数据源中对“Semantic Web先生”的描述的新朋友的问候:
Run a Reasoner
Finally- Hello to all my friends!
Hello to I. M. Ontology
Hello to Ican Reason
Hello to Makea Statement
Hello to Mr. Owl
Hello to Web O. Data
2
3
4
5
6
7
8
但是有产生了新的问题,我们再次运行 hello.myself(hello.inferredFriends) ,会发现程序会向 SemanticWeb 先生问候两遍:
Hello to Semantic Web
Hello to Sem Web
2
原因在于模型中保存了“people:me 等价于 peopke:Individual_5”的信息,这样它就有了两个名字:Semantic Web 和 Sem Web。因为本体没有限制名字的数目,所有模型中想包含多少个就包含多少个。这个问题可以通过添加规则来解决,暂时先放着。
# TASK 3 仅仅向有邮件地址的那些朋友问好
这个目标其实是相当于将已有的朋友分组。我们将有邮件地址的朋友成为“Email 朋友”,这样 Email 朋友便只能是一个 Person,并且有一个 foaf:mbox 的关系。有多种方式可以实现这一目标,不过我们希望本体能够包含这一信息,因此我们创建了一个特定的类 EmailPerson,形成一个约束,该约束为受限类描述了成员关系的逻辑。下面给出针对 Email 朋友的约束:
@prefix : <http://org.semwebprogramming/chapter2/people#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
:EmailPerson
rdf:type owl:Class ;
owl:equivalentClass [
rdf:type owl:Restriction ;
owl:minCardinality "1"^^xsd:nonNegativeInteger ;
owl:onProperty foaf:mbox
].
2
3
4
5
6
7
8
9
10
11
12
- 该约束的目的是为了限定类 people:EmailPerson 必需至少有一个 foaf:mbox。
现在我们将约束读入到与推理机绑定的模型中,并且查询 Email 朋友:
System.out.println("\nEstablishing a restriction to just get email friends");
hello.setRestriction(hello.inferredFriends);
hello.myEmailFriends(hello.inferredFriends);
public void setRestriction(Model model) throws IOException{
// Load restriction - if entered in model with reasoner, reasoner sets entailments
InputStream inResInstance = FileManager.get().open("Ontologies/restriction.owl");
model.read(inResInstance,defaultNameSpace);
inResInstance.close();
}
public void myEmailFriends(Model model){
//just get all my email friends only - ones with email
runQuery(" select DISTINCT ?name where{ ?sub rdf:type <http://org.semwebprogramming/chapter2/people#EmailPerson> . ?sub foaf:name ?name } ", model); //add the query string
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
运行后得到结果:
Establishing a restriction to just get email friends
Hello to Makea Statement
Hello to Ican Reason
Hello to I. M. Ontology
2
3
4
# TASK 4 仅仅向有 Gmail 邮箱的朋友问好
此约束要求朋友的邮箱地址必须是 gmail.com 类型的。这一需求超出了本体构造的能力,因为我们需要一种能够实现字符串部分匹配的方法,不过这种构造在 OWL2 中才得以实现。我们将使用语义 Web 规则来实现这个目标。
和推理机类似,规则引擎也有多种类型,而且每一种都有自己的规则语言。我们在本例中使用 Jena Rule。我们建立这样一条规则:找到 gmail.com 邮件地址并且创建一个陈述将实例主语和一个 GmailPerson 本体类相关联。规则是支持两个本体之间转换操作的好工具。请注意,一个个体资源可以是多个类的实例。
private void runJenaRule(Model model){
String rules = "[emailChange: (?person <http://xmlns.com/foaf/0.1/mbox> ?email), strConcat(?email, ?lit), regex( ?lit, '(.*@gmail.com)') -> (?person <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://org.semwebprogramming/chapter2/people#GmailPerson>)]";
Reasoner ruleReasoner = new GenericRuleReasoner(Rule.parseRules(rules));
ruleReasoner = ruleReasoner.bindSchema(schema);
inferredFriends = ModelFactory.createInfModel(ruleReasoner, model);
}
2
3
4
5
6
7
字符串rules中存放着规则,在此该规则会查找和foaf:mbox相关的声明,然后使用一个规则方法regex()来为 gmail.com 测试 foaf:mbox 入口。如果 foaf:mbox 和 gmail.com 中的每个条件都为真,则将会向模型中添加一条陈述,将匹配的人员实例和类 person:GmailPerson 关联起来。因此,查找 GmailPerson 的查询会返回所有拥有一个 gmail.com 地址的 foaf:Person。正如前面所提到的,您的程序仅仅需要将推理机绑定到恰当的模型上即可。一旦绑定,推理机就会适时进行工作。因此如果添加了一个有 gmail.com 邮件地址的新朋友,推理机就会按照规则将该朋友作为一位 person:GmailPerson.。
运行后可看到成功结果:
Say hello to my gmail friends only
Hello to Makea Statement
Hello to I. M. Ontology
2
3
到此,我们的任务也就完成了。