 现实世界中的知识建模
现实世界中的知识建模
# chapter 5 现实世界中的知识建模
本章概览:本章将讲述如何在现实世界中使用本体,从中您可以学习到
- 本体如何与实际的应用程序融为一体
- 推理的概念以及它对实现 OWL 的语义有多重要
- 几种 OWL profile,它们的用途,以及如何借助它们为那些使用OWL的系统提供令人满意的计算特性
- 信息管理应用程序的重要设计原则
# 5.1 探究语义 Web 的组件
在下面这个例子中:
ex:Canine rdf:type owl:Class;
rdfs:subClassOf ex:Mammal.
ex:Daisy rdf:type ex:Canine.
2
3
4
显式的信息是知道了 Daisy 是 Canine 类型,但又由于 Canine 是 Mammal 的子类,所以 Daisy 又是一个哺乳动物的这个事实却是隐含的。
OWL 仅仅是一种本体语言,而不是一个应用程序。因此,OWL 本身其实并不能完成任何工作。OWL 是描述语义和定义知识模型的一种工具。为了能够发挥OWL 的语义描述能力,很多语义 Web 应用程序都通过一个集成组件的框架来提供RDF 信息的存储和检索功能,以及对 OWL 语义的解释。知识库是一种软件组件,用来表示一个在语义 Web 应用程序中基于本体描述的、处理和访问的信息集合。为了能够提供这样的功能,框架由一系列工具组成,包括 RDF 存储(通常也被称作是三元组存储或者图存储)、一套访问 API 或者查询处理程序以及一个推理引擎(或者推理机)。因为语义 Web 的组件建立在开放式标准接口、语言和协议的基础之上,所以在定制这些框架的时候,开发人员有大量的组件可供选择。
# 5.1.1 语义 Web 框架
这些框架通常由三种基础组件所组成:存储、访问和推理。从根本上来讲,知识库是一个事实(陈述)的集合。语义Web 框架的组件用于存储这些事实,并且提供对这些事实的访问和推理。事实既可以是显式的也可以是隐含的。显式的事实是指那些在知识库中直接进行了声明的事实,隐含的事实则是蕴含,知识库中的显式事实本体语义和规则联合起来暗示了这种事实的存在。蕴含由知识库的推理组件所驱动。根据实现的不同,蕴含既可以按照底层的存储机制直接存储,也可以根据需要当从知识库检索信息时推导生成。
大多数语义 Web 框架的模块化设计都允许开发人员对框架的各个方面进行定制,以便针对某个特定的需求集合来优化知识库。例如,如果应用程序需要一种运行速度极快的系统,在只有少量 OWL 语义支持的前提下能够对大容量数据进行操作,则知识库应当将高伸缩性的持久性 RDF 存储和快速检索工具及小型推理组件集成到一起。如果需求中要求有完整的 OWL 推理功能,但是又没有提到可伸缩性和大数据量,那么应当将轻量级的内存 RDF 存储和强大的推理功能组合到一起使用。在构建语义 Web 应用程序时进行上述这样的权衡是很常见的,因为日益增长的本体复杂度会对运算性能提出更高的要求,而这些运算开销大多来源于对蕴含的计算。
# 5.1.2 存储和检索 RDF
框架中的存储和访问机制有多种,既可以是带有检索 API 的小型 in-memory 模型,也可以是能够存储数十亿条陈述的基于服务器的RDF存储(带有能够并行处理数百条查询的查询处理器)。语义 Web 框架存储组件的具体实现对用户来说通常是透明的,因为用户通常仅仅通过访问组件来与其交互。
基于图模型的 RDF 存储是一种能够更加直接地对 RDF 数据的结构进行建模的数据结构,它的出现缓解了基于关系模型存储的性能问题。给定一条特定的陈述,基于图的存储能够提供一种高效方式来定位与之共享相同资源(主语、谓语和宾语)的陈述,因为按照这种设计,它们会以高度的区域性(这就是说它们的存储位置相互临近)进行存储。常见的基于图的 RDF 存储的实现使用了相互链接的陈述列表,这样每条共享相同资源(这些资源可能作为陈述主语、谓语或者宾语)的陈述就被安置到了一个连续的链接列表中,或者使用特殊的索引数据结构来链接在RDF图中相邻(连接)的陈述。这样就提供了一种机制可以快速遍历包含某一特定资源(在陈述中作为主语、谓语或者宾语)的所有陈述。
在知识库中访问信息最常用的方法是使用查询接口。SPARQL 协议与查询语言是语义 Web 的推荐查询语言。查询处理器接收 SPARQL 查询并且将查询分发给底层知识库的RDF存储,进而以表或者 RDF 的形式生成结果集。
# 5.1.3 正向推理与反向推理
使用 OWL 最大的好处在于能够定义语义,而语义又充实了信息。正如前面所提到的,知识库需要使用推理组件来解释语义并了解这些富语义的信息。执行推理的应用程序通常被称作推理引擎或者推理机。推理引擎是这样一个系统,它能够基于知识库中已有的内容推理出新的信息。
很多语义 Web 框架都使用基于规则的推理引擎来执行推理。这些引擎通过将知识库中所包含的断言和一个逻辑规则集合组合起来推导断言或执行某些动作。规则包含两个部分,可以构建成一条 if-then 陈述。第1部分是规则的条件,而第2部分是规则的结论。规则可以用于表达 OWL 的大部分语义,并且可以作为一种工具,供用户表达任意无法在 OWL 中建模的关系。根据应用程序的不同,规则的种类也有很多种。一个规则确立了一个能够匹配规则条件的陈述集合,规则结论中的陈述在知识库中是隐含的。
通常推理功能直接被集成到知识库中,而且对用户是透明的。在有些应用程序中,推理是作为外部组件实现的,以手工方式启动,而且蕴含是被手工添加到知识库中的。在基于规则的推理机中执行推理主要有两种方式:正向链接推理和反向链接推理。有些系统将两种方式组合到一起使用,也称作混合推理。
# 1)理解正向链接推理
在正向链接推理中,所有的蕴含(隐含事实)都直接在知识库中断言。无论何时添加新的事实都会发生正向链接推理,而且作为同一操作的一部分,蕴含的陈述也会被立即添加到知识库中。结果是,知识库总是包含所有显式断言的事实和隐式断言的事实。正向链接之所以得名,是因为推理的执行过程是从知识库中的数据和规则向着它们所隐含的蕴含进行的。下图演示了正向链接推理的过程。刚开始,事实 1 和事实 2 是知识库中唯一的显式事实。事实 1 蕴含了事实 3、事实 4 和事实 5 的存在。当加入了事实 6 之后,正向链接推理过程就会导出事实 7、事实 8 和事实 9 的蕴含,并且最终导出事实 10。
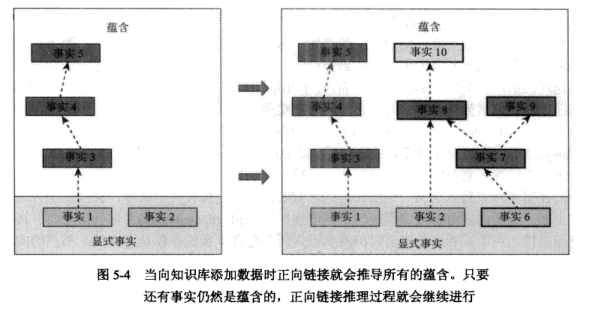
每当添加一个新的显式事实之后,则新的蕴含就会被推导出来。然而,正如这个例子所表明的那样,大量其他事实也被添加到了知识库中。如果您仅仅关注事实10的存在,那么您会发现:在正向链接推理过程中将使知识库变大,并且要在那些您并不需要的事实上花费额外的时间进行推理。正向链接推理方法增加了存储规模,而且如果要提高知识库检索性能,就需要在插入和删除操作上花费过多的开销。因为所有的蕴含都会被推导出来并作为数据存储起来,因此当进行检索操作的时候就不需要再进行额外推理,提高了检索速度。
如果您需要删除前面已经声明了的陈述,那么使用正向链接就有问题了。删除以前声明的陈述可能会导致出现以下这样的情况:尽管一条陈述不应当存在于知识库中,但是它实际上却依然存在(也就是说,该陈述以前被声明为某一事实的蕴含,而该事实现在被删除了)。上面介绍的问题对于知识库中的“真值维护”工作非常重要。真值维护问题是指当声明或者删除事实时仍然要确保所有蕴含事实的存在是合法的。不正确的真值维护会很快导致知识库不一致,使之包含不合法的蕴含或者矛盾的信息。当删除事实时,真值维护过程会将原先由于它的加入而被推理出来的所有事实都删除。多个事实可能会产生相同的蕴含,而被删除的事实本身也可能是蕴含,导致知识库中显式事实和隐含事实之间的相互关系非常复杂,因此,要追踪某个事实并且保证该事实能够被正确删除是一件非常复杂的工作。大多数知识库解决方案要么无法执行真值维护,要么采用了非常简单的处理方法,即在删除一个或多个事实之后直接将所有蕴含事实全部清除,再重新执行争相链接推导。
# 2)理解反向链接推理
反向链接是推理引擎执行推理的另一种主要方式。在反向链接推理中,推理的执行通过借助反向应用系统逻辑来导事实目标集合的条件(某条规则的条件或者某个查询的模式),直到知识库中的显式事实能够满足条件为止。下图描述了这个过程。同样,我们的目标是确定知识库中是否含有事实10。反向链接推理要确定事实10是否能够由知识库中的显式事实推导得出,它是通过确定哪些事实会推导出事实10这一蕴含来完成这一目标的。在本例中,由于事实8蕴含了事实10的存在,所以推理过程必须确定事实8是否可以被推导出来。而事实8又是由事实2和事实7联合推导出来的。事实2已经存在,因此推理过程必须转而确定事实7是否可推导出来。事实7由事实3蕴含,而事实3又在知识库中显式存在。因此,可以确定知识库中包含事实1。如果在推理过程中这些事实中有任何一个缺失了,则意味着事实10不会包含在知识库中。

反向链接推理是极具吸引力的,因为只有当有必要对某一事实是否存在进行验证时才会推导出蕴含。这样一来就避免了知识库中不必要的事实扩展,同时也没有为陈述的添加和删除带来额外的开销。一旦事实通过反向链接推导出来,它们不会像正向链接那样在知识库中持久化(尽管为了提高性能可能会将它们存储在高速缓存中)。反向链接最主要的优点之一是极大地简化了真值维护,因为只有显式事实才会在知识库中持久化,而且对已声明的陈述进行删除操作并不会影响到知识库中的其他陈述。 反向链接同样也存在缺陷,它将正向链接中插入和删除.上的开销转移到了访问上。这意味着使用AP或者查询接口访问知识库中的信息会花费更多的计算和更高的代价。在很多知识库系统中,查询时间是最为关键的性能指标之一。如果不进行缓存,当需要重复多次地对某个查询进行应答时,则反向链接系统的效率就可能会非常低,因为在这个过程中将重复执行同一个蕴含过程。
# 3)选择正确的推理方法
选择正确的推理方法通常可以用这样一个问题来描述:评估需求和约束,并且确定哪一种方式最适用于给定的应用程序。大多数框架都提供了正向链接知识库,因为这种知识库更加容易实现,而且在进行插入和删除操作的过程中知识库增加的规模和计算需求是可接受的。正向链接在执行查询操作上的性能远优于执行插入操作和删除操作的性能,而且在大多数应用程序中,查询是最经常执行的操作。 当本体经常变化或者知识库经常需要进行修改(包括陈述的删除)时,反向链接通常就成为很好的选择。这是因为反向链接不会对底层存储的信息产生任何影响,而且对这些信息的任何修改都无需考虑推理方式所产生的影响。由于使用分布式推理系统时不存在集中式的知识库,所以此时采用反向链接方式就非常必要了。这种情况下,由于没有一个可用于执行正向链接并存储蕴含的知识库,因此必须使用一种基于反向链接的方式来扩展和分发查询。
# 5.2 探索 OWL Profile
# 5.2.1 OWL Full、DL 和 Lite
最初的 OWL 规范和 OWL 2 都提供了profile,也就是说 OWL 语言的子语言通过放弃某些表达能力换取了计算方面的效率。这些 profile 在使用OWL时引入了限定语法和非结构化的约束。在原来的OWL规范中,有三种 profile 类型:OWL Full、OWL DL 和 OWL Lite。其中,OWL Full 是完整的、不受限的 OWL 规范。OWL DL 在OWL Full 的基础上引入了很多约束,包括将类和个体分离开来。设计这些约束是为了使 OWL DL 可判定。OWL Lite 本质上是 OWL DL 语言元素的-一个子集。
- 引入OWL Lite 的目的是为应用程序和工具的开发人员提供开发目标,即提供一个能够支持 OWL 1 特性的起点。遗憾的是,人们认为 OWL Lite 在很大程度上是失败的,因为它去除了 OWL 中太多有用的特性,同时又没有带来足够多的计算方面的好处,即没有在消减特性的同时变得更具吸引力。
- OWL DL 则更为成功一些,它提供了描述逻辑的很多功能,然而,当处理普通的知识库时,尽管它是可判定的,但是并不能保证只要正确地执行就能够得到所期望的性能。从理论上讲,如果一种推理算法在“宇宙热寂”之前无法得到所希望的结果,那么即使最终完成了推理也是没有意义的。这并不是说 OWL DL 推理通常要花费数不清的年代才能完成,而是为了说明其判定性无法和现实需求同步。
- 可判定性规定,只有存在能够提供完备推理的算法才是可判定的。这并不对算法性能提出要求。
- OWL Full 的引入主要是为了与 RDF 和 RDF Schema 相兼容。OWL Full 保留了描述任意事物所有特征的能力,但它是不可判定的,即目前尚没有出现能够基于复杂的 OWL Full 知识库推理出所有语义蕴含的算法。
# 5.2.2 OWL Profile
OWL profile 的主要目的是生成几个 OWL 语言的子集,这些子集以牺牲某些表达能力换取更好的计算性能。Profile 是为特殊的用户群体和实现技术而开发的。在本书撰写之际,存在3种标准的 OWL profile:OWL EL、OWL QL 和 OWL RL。每一种 profile 都是通过对 OWL DL 进行限定而得到的。
注意:理解OWL profile的内涵非常重要。您很少会用到OWL Full。OWL DL 和 OWL profile 才真正使 OWL 的应用变成了现实。
可以到 W3C 网站上下载 OWL 2 的 Profile 文档 (opens new window) ,通过查阅该文档中的完整列表来查看详细的特性。
# 5.3 OWL 推理演示
本节给出了一个实用的例子,在包含一个简单的 OWL 本体的知识库中实现了多个层次的推理。在本例中使用的知识库是一个 Jena 模型,而本体则是我们之前给出的人和犬科动物的例子。我们需要考虑 3 个层次的推理:无推理、RDFS 层面上的推理和 Pellet 提供的 OWL 层面上的推理。在下面的例子中,我们将首先概述本体和应用程序,然后讲述在每个推理层次上运行应用程序的结果,并且揭示各种知识模型中信息的差异。
# 5.3.1 本体
接下来会对本体每一部分给出说明,完整本体在最后给出。它不遵从哪一个特定的 Profile,但该本体仍然处在 OWL DL 范围之内。我们已经定义了一些类和属性,也定义了一些个体(但一般情况下个体都不包含在本体之内)。
首先,我们给出了 ex:Mammal 和 ex:Human 的简单定义,且 ex:Human 是 ex:Mammal 的子类:
ex:Mammal rdf:type owl:Class.
ex:Human rdf:type owl:Class;
rdfs:subClassOf ex:Mammal.
2
3
4
接着,我们将类 ex:Canine 定义为类 ex:Mammal 的子类,并对其应用了一个值约束:它至少有一个 ex:breed 属性且属性值为类 ex:Breed 的实例:
ex:Canine rdf:type owl:Class;
rdfs:subClassOf ex:Mammal;
owl:equivalentClass [
rdf:type owl:Restriction;
owl:onProperty ex:breed;
owl:someValuesFrom ex:Breed
].
2
3
4
5
6
7
接下来,使用 intersection-of 集合运算符定义 ex:PetOfRyan。这个类定义说明如果一个实例是类 ex:Mammal 的实例,并且他有一个 ex:hasOwner 属性且该属性值为 ex:Ryan,那么这个实例就是 ex:PetOfRyan 的一个实例:
ex:PetOfRyan rdf:type owl:Class;
owl:intersectionOf (
ex:Mammal
[
rdf:type owl:Restriction;
owl:onProperty ex:hasOwner;
owl:hasValue ex:Ryan
]
).
2
3
4
5
6
7
8
9
然后,我们定义了一个简单层次结构,该结构中包括品种类 ex:Breed 和它的两个子类 ex:LargeBreed 和ex:SmallBreed。然后我们定义了一个数据类型属性 ex:name 和三个对象属性 ex:breed、ex:hasOwner、和 ex:owns。在这里真正值得注意的一点是我们将 ex:registeredName 定义为了ex:name的一个子属性,而将 ex:owns 定义为了ex:hasOwner的逆属性:
ex:Breed rdf:type owl:Class.
ex:LargeBreed rdf:type owl:Class;
rdfs:subClassOf ex:Breed.
ex:SmallBreed rdf:type owl:Class;
rdfs:subClassOf ex:Breed.
ex:name rdf:type owl:DatatypeProperty.
ex:registeredName rdf:type owl:DatatypeProperty;
rdfs:subPropertyOf ex:name.
ex:breed rdf:type owl:ObjectProperty.
ex:hasOwner rdf:type owl:ObjectProperty.
ex:owns rdf:type owl:ObjectProperty;
owl:inverseOf ex:hasOwner.
2
3
4
5
6
7
8
9
10
11
12
13
最后定义了一些个体。前两个分别是 ex:GoldenRetriever(是 ex:LargeBreed 的一个实例)和 ex:Chihuahua(是ex:SmallBreed 的一个实例)。最后三个分别是 ex:Ryan、ex:Daisy 和 ex:Amber:
ex:GoldenRetriever rdf:type ex:LargeBreed.
ex:Chihuahua rdf:type ex:SmallBreed.
ex:Ryan rdf:type ex:Human;
ex:name "Ryan Blace";
ex:owns ex:Daisy.
ex:Daisy rdf:type ex:Canine;
ex:name "Daisy";
ex:registeredName "Morning Daisy Bathed in Sunshine";
ex:breed ex:GoldenRetriever.
ex:Amber rdf:type ex:Mammal;
ex:name "Amber";
ex:breed ex:GoldenRetriever.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
完整本体
@prefix ex: <http://example.org#>.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>.
@prefix owl: <http://www.w3.org/2002/07/owl#>.
ex:Mammal rdf:type owl:Class.
ex:Human rdf:type owl:Class;
rdfs:subClassOf ex:Mammal.
ex:Canine rdf:type owl:Class;
rdfs:subClassOf ex:Mammal;
owl:equivalentClass [
rdf:type owl:Restriction;
owl:onProperty ex:breed;
owl:someValuesFrom ex:Breed
].
ex:PetOfRyan rdf:type owl:Class;
owl:intersectionOf (
ex:Mammal
[
rdf:type owl:Restriction;
owl:onProperty ex:hasOwner;
owl:hasValue ex:Ryan
]
).
ex:Breed rdf:type owl:Class.
ex:LargeBreed rdf:type owl:Class;
rdfs:subClassOf ex:Breed.
ex:SmallBreed rdf:type owl:Class;
rdfs:subClassOf ex:Breed.
ex:name rdf:type owl:DatatypeProperty.
ex:registeredName rdf:type owl:DatatypeProperty;
rdfs:subPropertyOf ex:name.
ex:breed rdf:type owl:ObjectProperty.
ex:hasOwner rdf:type owl:ObjectProperty.
ex:owns rdf:type owl:ObjectProperty;
owl:inverseOf ex:hasOwner.
ex:GoldenRetriever rdf:type ex:LargeBreed.
ex:Chihuahua rdf:type ex:SmallBreed.
ex:Ryan rdf:type ex:Human;
ex:name "Ryan Blace";
ex:owns ex:Daisy.
ex:Daisy rdf:type ex:Canine;
ex:name "Daisy";
ex:registeredName "Morning Daisy Bathed in Sunshine";
ex:breed ex:GoldenRetriever.
ex:Amber rdf:type ex:Mammal;
ex:name "Amber";
ex:breed ex:GoldenRetriever.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# 5.3.2 示例应用程序
这里只对部分代码展开说明,完整代码在最后给出,程序运行环境与第二章的相同。
该应用程序用于演示在刚刚介绍的知识模型上进行多个层次的推理效果,该程序有 4 个命令行参数:输入文件、输入文件格式(N3、RDF/XML、Turtle 等)、输出文件和推理层次(none、rdfs 或 owl)。
首先,应用会解析各个输入参数;
然后,会创建一个 Jena 的 model 用于存放各陈述,并根据推理模式的不同,采用不同的方式来创建出这个OntModel 类型的 model:
OntModel model = null; // create the appropriate jena model
- 如果设置无推理模式(“none”),则程序会使用 OntModelSpec.OWL_DL _MEM 创建了一个基本的本体模型。这规定了 Jena 应当载入 RDF、RDFS 和 OWL 本体,但是在模型上不进行推理操作:
if ("none".equals(reasoningLevel.toLowerCase()))
{
/*
* "none" is jena model with OWL_DL
* ontologies loaded and no inference enabled
*/
model = ModelFactory.createOntologyModel(
OntModelSpec.OWL_DL_MEM);
}
2
3
4
5
6
7
8
9
- 当运行在 RDFS 模式时,模型是使用 OntModelSpec.OWL_DL_MEM_RDFS_INF创建的。这个模型也将载入RDF、 RDFS 和 OWL 本体,然而,程序将使用 Jena 自带的内置推理引擎进行 RDFS 推理。这就意味着推理应当在所有 RDFS 词汇表元素(属性和类层次关系、定义域、值域等)之上进行:
else if("rdfs".equals(reasoningLevel.toLowerCase()))
{
/*
* "rdfs" is jena model with OWL_DL
* ontologies loaded and RDFS inference enabled
*/
model = ModelFactory.createOntologyModel(
OntModelSpec.OWL_DL_MEM_RDFS_INF);
}
2
3
4
5
6
7
8
9
- 最后一种模式是关于 OWL 的,这种模式要比前两种进行更多设置。首先,我们使用
PelletReasonerFactory类创建一个新的 Reasoner 实例。然后,我们使用 Jena 的ModelFactory类创建一个Jena推理模型,将参数设置为 Pellet 推理机和一个新创建的空 Jena 模型。最后,我们创建出自己真正的 Jena OntModel,该模型包装了我们刚刚创建的 Pellet 推理模型,而且同样载入了 RDF、RDFS 和 OWL 本体。这段代码的效果就是产生了一个能够使用 Pellet OWL 推理机来完成推理过程的 Jena 本体模型:
else if("owl".equals(reasoningLevel.toLowerCase()))
{
/*
* "owl" is jena model with OWL_DL ontologies
* wrapped around a pellet-based inference model
*/
Reasoner reasoner =
PelletReasonerFactory.theInstance().create();
Model infModel = ModelFactory.createInfModel(
reasoner, ModelFactory.createDefaultModel());
model = ModelFactory.createOntologyModel(
OntModelSpec.OWL_DL_MEM, infModel);
}
2
3
4
5
6
7
8
9
10
11
12
13
之后,当我们以上述 3 种方式之一创建模型之后,再使用 model.read(…) 将本体装载到模型当中。推理是自动进行的,因此不需要进行显式的操作来保证所有的蕴含都能够正确导出:
model.read(inputStream, null, inputFileFormat);
最后一部分将基于模型中所有个体组成的列表进行迭代,并且将所有以这些个体为主语的陈述都以摘要的形式打印到输出文件:
ExtendedIterator iIndividuals = model.listIndividuals();
while(iIndividuals.hasNext())
{
Individual i = (Individual)iIndividuals.next();
printIndividual(i, writer);
}
iIndividuals.close();
writer.close();
model.close();
2
3
4
5
6
7
8
9
10
完整代码
package net.semwebprogramming.chapter5.PelletReasoning;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.PrintWriter;
import java.util.Iterator;
import org.mindswap.pellet.jena.PelletReasonerFactory;
import com.hp.hpl.jena.ontology.Individual;
import com.hp.hpl.jena.ontology.OntModel;
import com.hp.hpl.jena.ontology.OntModelSpec;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.rdf.model.ModelFactory;
import com.hp.hpl.jena.rdf.model.Statement;
import com.hp.hpl.jena.rdf.model.StmtIterator;
import com.hp.hpl.jena.reasoner.Reasoner;
import com.hp.hpl.jena.reasoner.ValidityReport;
import com.hp.hpl.jena.util.iterator.ExtendedIterator;
public class InferenceExample
{
/**
* This program takes 4 parameters an input file name
* an output file name an input file format a reasoning
* level {RDFS, OWL-DL}
*/
public static void main(String[] args)
{
//validate the program arguments
if(args.length != 4)
{
System.err.println("Usage: java InferenceExample "
+ "<input file> <input format> <output file> "
+ "<none|rdfs|owl>");
return;
}
String inputFileName = args[0];
String inputFileFormat = args[1];
String outputFileName = args[2];
String reasoningLevel = args[3];
//create an input stream for the input file
FileInputStream inputStream = null;
PrintWriter writer = null;
try
{
inputStream = new FileInputStream(inputFileName);
} catch (FileNotFoundException e) {
System.err.println("'" + inputFileName
+ "' is an invalid input file.");
return;
}
//create an output print writer for the results
try
{
writer = new PrintWriter(outputFileName);
} catch (FileNotFoundException e) {
System.err.println("'" + outputFileName
+ "' is an invalid output file.");
return;
}
//create the appropriate jena model
OntModel model = null;
if("none".equals(reasoningLevel.toLowerCase()))
{
/*
* "none" is jena model with OWL_DL
* ontologies loaded and no inference enabled
*/
model = ModelFactory.createOntologyModel(
OntModelSpec.OWL_DL_MEM);
}
else if("rdfs".equals(reasoningLevel.toLowerCase()))
{
/*
* "rdfs" is jena model with OWL_DL
* ontologies loaded and RDFS inference enabled
*/
model = ModelFactory.createOntologyModel(
OntModelSpec.OWL_DL_MEM_RDFS_INF);
}
else if("owl".equals(reasoningLevel.toLowerCase()))
{
/*
* "owl" is jena model with OWL_DL ontologies
* wrapped around a pellet-based inference model
*/
Reasoner reasoner =
PelletReasonerFactory.theInstance().create();
Model infModel = ModelFactory.createInfModel(
reasoner, ModelFactory.createDefaultModel());
model = ModelFactory.createOntologyModel(
OntModelSpec.OWL_DL_MEM, infModel);
}
else
{
//invalid inference setting
System.err.println("Invalid inference setting, "
+ "choose one of <none|rdfs|owl>.");
return;
}
//load the facts into the model
model.read(inputStream, null, inputFileFormat);
//validate the file
ValidityReport validityReport = model.validate();
if(validityReport != null && !validityReport.isValid())
{
Iterator i = validityReport.getReports();
while(i.hasNext())
{
System.err.println(
((ValidityReport.Report)i.next()).getDescription());
}
return;
}
//Iterate over the individuals, print statements about them
ExtendedIterator iIndividuals = model.listIndividuals();
while(iIndividuals.hasNext())
{
Individual i = (Individual)iIndividuals.next();
printIndividual(i, writer);
}
iIndividuals.close();
writer.close();
model.close();
}
/**
* Print information about the individual
* @param i The individual to output
* @param writer The writer to which to output
*/
public static void printIndividual(
Individual i, PrintWriter writer)
{
//print the local name of the individual (to keep it terse)
writer.println("Individual: " + i.getLocalName());
//print the statements about this individual
StmtIterator iProperties = i.listProperties();
while(iProperties.hasNext())
{
Statement s = (Statement)iProperties.next();
writer.println(" " + s.getPredicate().getLocalName()
+ " : " + s.getObject().toString());
}
iProperties.close();
writer.println();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
# 5.3.3 运行结果
# 1)执行无推理模式
在无推理模式下,我们希望看到的真正示例本体中表达的个体和陈述集合,输出结果没有给出额外的陈述,因为程序并没有推理出额外的陈述:
Individual: Chihuahua
type : http://example.org#SmallBreed
Individual: GoldenRetriever
type : http://example.org#LargeBreed
Individual: Daisy
breed : http://example.org#GoldenRetriever
registeredName : Morning Daisy Bathed in Sunshine
name : Daisy
type : http://example.org#Canine
Individual: Ryan
owns : http://example.org#Daisy
name : Ryan Blace
type : http://example.org#Human
Individual: Amber
breed : http://example.org#GoldenRetriever
name : Amber
type : http://example.org#Mammal
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 2)执行 RDFS 推理模式
这种模式下可以看到 RDFS 语义能够推理出来的结果,在本例中,子类和子属性关系都会产生作用:
Individual: Chihuahua
type : http://example.org#SmallBreed
+ type : http://example.org#Breed
Individual: GoldenRetriever
type : http://example.org#LargeBreed
+ type : http://example.org#Breed
Individual: Daisy
breed : http://example.org#GoldenRetriever
registeredName : Morning Daisy Bathed in Sunshine
name : Daisy
type : http://example.org#Canine
+ name: Morning Daisy Bathed in Sunshine
+ type : http://example.org#Mammal
Individual: Ryan
owns : http://example.org#Daisy
name : Ryan Blace
type : http://example.org#Human
+ type : http://example.org#Mammal
Individual: Amber
breed : http://example.org#GoldenRetriever
name : Amber
type : http://example.org#Mammal
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
与无推理模式的输出结果的区别已被标出。该输出文件中包含一些由类和属性间的分类学关系推理出来的结果。这些结果中含有的事实包括:
- 吉娃娃(Chihuahua)和金毛猎犬(Golden Retriever)都是品种
- Daisy的注册名也是一个名称,Daisy不仅仅是一个犬科动物,而且还是一个哺乳动物。
这些都是从 RDFS 名称空间中构造出来的语义的结果。这其中有些蕴含的推导是因为子类关系导致某个实例成为了某个父类的成员。而另一些蕴含的导出则是因为子属性关系导致某个实例中添加了某个新属性。因为我们仅仅提供了RDFS推理,因此我们仍然无法看到OWL语义所蕴含的新信息,这其中包括的事实有:Amber是一个犬科动物,ex:owns 和 ex:hasOwner 之间存在的逆属性关系意味着Daisy的主人是Ryan。
# 3)执行 OWL 推理模式
在这个例子中,因为 Pallet 支持我们在示例本体中的使用的所有 OWL 和 RDFS 构造,所以我们应当在结果中看到所有的隐含陈述:
Individual: Ryan
owns : http://example.org#Daisy
name : Ryan Blace
type : http://example.org#Human
+ type : http://www.w3.org/2002/07/owl#Thing
type : http://example.org#Mammal
+ sameAs : http://example.org#Ryan
Individual: GoldenRetriever
type : http://example.org#LargeBreed
+ type : http://www.w3.org/2002/07/owl#Thing
type : http://example.org#Breed
+ sameAs : http://example.org#GoldenRetriever
Individual: Chihuahua
+ type : http://www.w3.org/2002/07/owl#Thing
type : http://example.org#Breed
type : http://example.org#SmallBreed
+ sameAs : http://example.org#Chihuahua
Individual: Amber
breed : http://example.org#GoldenRetriever
name : Amber
+ type : http://www.w3.org/2002/07/owl#Thing
+ type : http://example.org#Canine
type : http://example.org#Mammal
sameAs : http://example.org#Amber
Individual: Daisy
registeredName : Morning Daisy Bathed in Sunshine
breed : http://example.org#GoldenRetriever
+ hasOwner : http://example.org#Ryan
name : Morning Daisy Bathed in Sunshine
name : Daisy
+ type : http://www.w3.org/2002/07/owl#Thing
type : http://example.org#Canine
+ type : http://example.org#PetOfRyan
type : http://example.org#Mammal
+ sameAs : http://example.org#Daisy
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
现在知识模型中有了很多新的陈述,所有从 RDFS 推理示例中得到的推理结果仍然位列其中。此外,所有的个体现在都是 owl:Thing 类的成员了。这是因为我们现在处于 OWL 语义的范畴之内,所以所有的实例都应当是 owl:Thing 类的成员。值得一提的是所有实例都和其自身是 owl.sameAs 的。依据推理引擎的具体实现的不同,您可能会发现类似这样的陈述在技术上都是合理的,尽管它们并不一定很有用。
- Daisy确实有了主人Ryan。Daisy和Ryan之间已经正确地建立起了has-owner关系,类 ex:PetOfRyan 也得以正确解释,而且Daisy是该类的一个成员,因为它有 ex:hasOwner 属性,并且该属性的值为 ex:Ryan。
- OWL 语义也得以正确解释,Amber 必然是一个犬科动物,因为她有一个 ex:breed 属性,而该属性指向ex:Breed类的一个实例。
这个练习演示了 RDFS 和 OWL 语义的具体运作过程。RDFS 引入了属性和类的分类学结构,从而使您可以利用陈述和类成员的自动传播。OWL 通过使用约束和高级类描述以及属性描述增加了更多的表达能力。包含 OWL 构造的本体仍然可以在仅仅应用RDFS模式或无推理模式的应用程序中使用,不过,您将无法识别出所有的本体语义,除非您所使用的推理层次能够支持您在本体中所使用的构造。