 语义Web基础
语义Web基础
语义 Web 程序设计涵盖了两个基本方面:知识表示和应用程序集成。本部分重点在于知识表示——使用资源描述框架(RDF)、数据模型、本体(OWL)、查询、规则和推理来实现知识的表示和操作。
# chapter 3 信息建模
在语义 Web 上,信息建模主要借助于一个互补的语言集合——RDF(资源描述框架)、RDFS(RDF Scheme)和 OWL Web 本体语言。本章主要介绍 RDF,它定义了底层的数据模型。
# 3.1 软件中的信息建模
语义 Web 技术的信息模型的设计目标是为了使数据共享和交互操作更加便捷。
# 3.1.1 共享信息:语法和语义
系统之间共享数据的问题可以分解为——语法共享问题(选媒介)和语义共享问题(选语言或编码方式)。
- 语法:信息传输的方式
- 语义:共享信息的概念或者含义
有以下三种信息表示方式来表达共享数据的含义:
- 序列化对象:最简单直接,但要求接收者对发送者的数据结构十分了解;
- 关系数据库:虽然有了标准的 API(如 ODBC、JDBC)和 SQL 语句,但也面临驱动程序版本等不同的问题,比如接收者不知道发送者使用的是 Oracle 还是 SQL Server;
- 可扩展标记语言(XML):虽然流行且灵活,但缺乏保留字,且其元素和属性本身没有含义,因此标签的顺序改变或术语变化都会给开发者带来大量工作。
实际上,数据共享语义层问题的进展源自与这样的感悟:数据和元数据之间的差异其实是一种错觉。
# 3.1.2 信息共享中的元数据和数据
数据是数值,是信息的个体原子;元数据描述了这些原子和其他数据之间的关系。比如数据库中的记录是数据,而表格的模式是元数据。
为了使计算机能够自动共享信息,就应当将数据和元数据归为一类。从某种意义上说,没有元数据就没有了谈话的主题,而没有数据就没有了要说的内容。将元数据和数据组合在一起便于信息的移植,极大减少了信息共享的问题,另外这种做法还提供了更大的灵活度,因为已有的信息可以通过额外的元数据来进行扩展。
# 3.2 语义 Web 信息模型:RDF
在语义 Web 上,信息被表示成陈述(Statement)的集合。
陈述由主语、谓语和宾语组成,也成为三元组(triple),比如 Andrew knows Matt。
- 我们约定:资源用椭圆表示,文字用矩形表示。
# 3.2.1 节点:资源或文字
RDF 图的节点有两种类型:资源(resource)和文字(literal)。
- 资源可以表示任何可以被命名的东西,如一个概念、某一本书、这个网页等;
- 文字是具体的数据值,如数字或者字符串。文字不能作为陈述的主语。
资源采用国际化资源标识符(IRI)的形式。IRI 是统一资源定位符(URI)的一种扩展,考虑到 IRI 和 URI 之间的相似性,往往两者可以混用。IRI 的一般形式:
比如 http://www.baidu.com:80/index.html、ftp://server.example.com/foo 等。IRI 是一个在全世界范围内唯一的名称,精确地描述了某个特定资源,它既可以是实体对象,也可以是抽象概念。这样 IRI 在任何上下文环境中都是合法的,因此也便于移植。
# 3.2.2 边:谓语
谓语也称作属性,用来描述资源之间的关联。谓语本身也是资源,也使用 IRI 来表示。
由于完整的 IRI 会使图显得混乱,因此我们一般使用带前缀的形式。
rdf:type 是 RDF 定义的一种特殊谓语,它用于将谓语归为一类。比如 p:Andrew rdf:type foaf:Person 表达了 Andrew 是一个人,这样也就为其赋予了一个类型。注意,一个资源可以不只有一个类型,也可以没有类型。
# 3.3 RDF 的序列化
我们可以将 RDF 陈述视作抽象三维空间上的一个点,坐标为 (s, p, o)。每个点是一个信息原子,这些点的集合表示成了一个 RDF 图。通过这种方式来考虑陈述可以看出这种表达方式为数据共享带来的一些好处:
- 便于合并:两个点集可以相互重叠,因此由多条陈述构成的两个图也可以合并成一个更为丰富的一个图。
- 无序:陈述是相互独立的,这意味着它们之间不存在次序上的先后问题。
- 无重复:如果两个陈述有相同的主谓宾,则它们是相同的。向一个集合中加入一个重复的陈述不会为整个集合贡献新的信息。
序列化提供了一种将抽象数据转换为具体格式(如文件或字节流)的方法,使其在不同程序间进行信息交换。有多种不同的序列化方式:
# 3.3.1 RDF/XML
RDF/XML 是一种表示 RDF 的 XML 语法,它是 RDF 序列化的官方标准(因为XML常用)。但遗憾的是,有了 RDF 基准格式却没有 RDF/XML 的标准表示,这使得同一个 RDF 图用不同的工具序列化而产生的结果也有所不同。
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:people="http://semwebprogramming.net/people#"
xmlns:ext="http://semwebprogramming.net/2008/06/ont/foaf-extension#">
<!-- This is a comment. -->
<rdf:Description rdf:about="http://sem../people#Ryan">
<rdf:type rdf:resource="http://xmlns.com/foaf/0.1/Person" />
<foaf:knows rdf:resource="http://sem../people#John"/>
<foaf:name>Ryan Blace</foaf:name>
<ext:year
rdf:datatype="http://www.w3.org/2001/XMLSchema#int">28</ext:year>
<foaf:givenname xml:lang="en">Ryan</foaf:givenname>
</rdf:Description>
</rdf:RDF>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
整体结构:所有 RDF 内容都包含在一个 rdf:RDF 标签中,该标签中又包含一系列 rdf:Description 元素。
各名称空间(前缀)是在 rdf:RDF 标签的一开始声明的。
http://www.w3.org/1999/02/22-rdf-syntax-ns该名称空间按照标准简写为 rdf,不论在哪种序列化方式中都是如此。
注释:与 XML 相同
陈述:被分组到
<rdf:Description>中,每个描述的rdf:about属性指定了主语,后续的描述定义了陈述的谓语和宾语。内部的标签表示一个谓语。对宾语的表述对资源和文字略有区别,可见上例。资源:主语的资源通过
<rdf:Description>的rdf:about属性指定;宾语出现在谓语标签的rdf:resource中。文字:作为谓语元素的文本内容出现。
- 文字可以被赋予一个标准的 XML Schema 数据类型(XSD),由
rdf:datatype指明如何处理文字值; - 字符串文字可以使用语言进行标记,由
xml:lang指明文本所使用的语言。合法的语言标签集合是有限制的,必须小写且每种语言编码都是通过 RFC3066 来确定的。可见上例。
- 文字可以被赋予一个标准的 XML Schema 数据类型(XSD),由
简写:为资源指定类型时可以简写:<type rdf:about="resource" />,例如
<rdf:Description rdf:about="#Ryan">
<rdf:type rdf:resource="http://xmlns.com/foaf/0.1/Person" />
</rdf:Description>
2
3
等价于
<foaf:Person rdf:ID="#Ryan" />
# 3.3.2 Turtle
Turtle 的可读性更好,专门为 RDF 设计。
@prefix foaf: <http://xmlns.com/foaf/0.1/>
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
@prefix ...
# This is a comment.
people:Ryan ext:workWith people:John .
people:Andrw
foaf:depiction <http://sem.org/semweb.jpg> ;
foaf:surname "Perez-Lopez"@en ;
foaf:knows people:Matt, people:Ryan, people:John ;
ext:year "4"^^<http://www.w3.org/2001/XMLSchema#int>
2
3
4
5
6
7
8
9
10
11
12
13
- 注释:用
#表示 - 陈述:一条主谓宾用空格隔开,以一个句点结尾。
- 同一主语的多条陈述可以简写,见上例的
people:Andrw,中间的每条陈述以冒号结尾。 - 当多条陈述有相同的主语和谓语时,不同宾语用逗号隔开,例子见
foaf:knows。
- 同一主语的多条陈述可以简写,见上例的
- 资源:两种写法:用
<>封闭起来的 URI 或预先定义好的前缀形式。 - 文字:被封闭在双引号中,内部可以使用
\来转义引号。含断行符的字符串可以使用三引号。- 数据类型通过向文字结尾处附加
^^<datatype URI>表示; - 语言由文字结尾处附加
@language来说明。
- 数据类型通过向文字结尾处附加
简写:字母 a 可以指代繁琐的 rdf:type 标记,如 :Ryan a foaf:Person 等价于 :Ryan rdf:type foaf:Person。
# 3.3.3 N-Triples
是 Turtle 的一种简化版本,它在注释、URI 和 文字值上都是用了与 Turtle 相同的语法,但不支持“@prefix”、“;” 以及 “,” 的陈述简写,使用一个包含主谓宾的行来陈述,单个陈述无法跨行。
# 3.3.4 格式转换
使用 Java 语言借由 Jena 可以实现不同格式的转换,但往往 Python 更易操作,可以使用 rdflib 库来完成:
from rdflib import Graph
g = Graph()
g.parse("<文件名>")
g.serialize(format="turtle", destination="<文件名>")
2
3
4
5
具体可见 rdflib官网 (opens new window)。
# 3.4 更多内容
# 3.4.1 空白节点
并非所有资源都指定了全球性名称空间中的 URI,有些资源从概念上讲根本没有名称,称作空白节点。比如你可以说“我的另一半一定是长得帅、性格耐心”,这里的“另一半”是一个存在变量,并没有真正描述任何单个实体,而是一个实体的抽象模板,用 RDF 描述说就是
我 期望的 另一半
另一半 长得 帅
另一半 性格是 耐心
2
3
这里的“另一半”就可以用一个空白节点表示。
比如我们想表达生活在某个州、某个城市的某个人,那就无法用一条陈述将一个资源既关联到城市,又关联到州。虽然可以用两个陈述,但无法解决一个人有多个住址的情况,用空白节点可以表示为:
# 第一个文件
sw:Bob sw:hasResidence _:residence .
_:residence sw:isInCity "Arlington" ;
sw:isInState "VA" .
# 第二个文件
sw:Bob sw:hasResidence _:bobhouse .
_:bobhouse sw:isInCity "Arlington" ;
sw:isInState "VA" .
2
3
4
5
6
7
8
9
这两个文件合并后将得到的结果是:
sw:Bob sw:hasResidence _:node .
_:node sw:isInCity "Arlington" ;
sw:isInState "VA" .
2
3
如果不适用空白节点的话,那这里只能用一个具体的 URI 来代替空白节点,这样两个文件合并后若表达住址的 URI 不完全相同的话,会产生两个住址的不被期望的结果。
在 Turtle 中为空白节点保留了一个特殊前缀:_:,例如 _:blanknode、_:placeholder、_:p3 等都是合法的空白节点。在单个 RDF 文档范围内,每个空白节点 ID 都是唯一的,比如 _:blanknode、_:placeholder是不同的空白节点,多个 _:blanknode 是指同一个空白节点。
对空白节点,Turtle 也提供了简写方式:用 [] 来定义一个空白节点,比如上例可以简写为:
sw:Bob sw:hasResidence [
sw:isInCity "Arlington" ;
sw:isInState "VA"
].
2
3
4
空白节点也带来了问题:
- 查询结果中若出现了空白节点,则赋给结果集的空白节点仅在该查询结果集中合法,无法在后继查询中直接引用该空白节点;
- 使 RDF 图的合并变得复杂,为了保证合并后的文档中空白节点的唯一性,需要使处理过程变得复杂。
# 3.4.2 具体化(Reification)
RDF 的陈述可以描述另一条陈述——即关于陈述的陈述。
- 用特殊类型
rdf:Statement指派一个资源是一个陈述。 - 谓语
rdf:subject、rdf:predicate、rdf:object用于定义准备注释的陈述。
比如要表达“Matt 说 John 认识 Ryan”:
:Matt :asserts _:stmt .
_:stmt a rdf:Statement ;
rdf:subject :John ;
rdf:predicate foaf:knows ;
rdf:object :Ryan .
2
3
4
5
这个例子使用一个空白节点来表示陈述资源,虽然也可以用完整 URI 来表示。
RDF 的扩展 RDF-star 提供了这种逻辑的简洁表达方式,具体可参考:
- RDF-star and SPARQL-star | W3C (opens new window)
- Support of RDF-star | Apache Jena (opens new window)
# 3.4.3 RDF 容器和列表
RDF 容器和列表用于为信息分组。
# RDF 容器
有三种资源类型,表示资源的集合:
- rdf:Bag:无序的资源分组
- rdf:Seq:有序的集合
- rdf:Alt:也是无序集合,但它在描述一个等价可替换值的集合时使用(用户仅可选择这些值的其中之一)
示例:
ex:Authors a rdf:Bag ;
rdf:_1 people:Ryan ;
rdf:_2 people:Matt ;
rdf:_3 people:Andrew .
ex:Chapters a rdf:Seq ;
rdf:_1 ex:ChapterOne;
rdf:_2 ex:ChapterTwo;
rdf:_3 ex:ChapterThree.
ex:HomePages a rdf:Alt ;
rdf:_1 <http://www.example.net>
rdf:_2 <http://www.example.org>
2
3
4
5
6
7
8
9
10
11
12
13
特殊的谓语集合rdf:_1、rdf:_2、rdf:_3.... rdf:_n关联了容器和资源。除了 rdf:Seq 外,n 的具体值可以忽略。也可以使用 rdf:li 来代替 rdf:_n,这样便不需要自己去维护 n 的数值。当使用 rdf:li 时,分组的第一个资源会变成 rdf:_1 、第二个变成 rdf:_2 ...
# RDF 列表
采用 rdf:_n 在合并时会出现 n 值的连续性问题,因此 RDF 提供了 rdf:List 构造的方式
ex:Authors a rdf:List ;
rdf:first people:Ryan ;
rdf:rest _:r1 .
_:r1 a rdf:List ;
rdf:first people:Matt ;
rdf:rest _:r2 .
_:r2 a rdf:List ;
rdf:first people:Andrew ;
rdf:rest rdf:nil .
2
3
4
5
6
7
8
9
列表是由两个谓语创建的,rdf:first 引出其中一个列表的第一个元素,rdf:rest 引出另一个列表。而其自身的 rdf:first 支持整个列表的第二个元素,依次递归进行下去,知道列表的 rdf:rest 为 rdf:nil 为止。这样合并时列表的内容和次序就不会变了。
尽管上面的构造方式有效,但表达出来十分晦涩,Turtle 提供了简洁的方式来表示 RDF 列表:
ex:Book ex:writtenBy (people:Ryan people:Matt people:Andrew) .
即使用圆括号表示列表,各资源之间用空格分开,这种简写形式与上面的 rdf:List 方式等价。
# chapter 4 融入语义
RDF 的灵活性和表达能力上的缺陷在于:如果单独使用,则无法对隐藏在各种描述之后的含义或者语义提供有力的支持,而 RDFS 和 OWL Web 本体语言则提供了这样的功能。
# 4.1 Web 上的语义
Web 上的大多数信息完全是以人类用户可读和可理解的形式存在的,而非被设计去让计算机理解。
使用语义最为明确并且最为微观的动因就是为了解决不同知识域之间的信息共享问题。对于数据库,若想实现两个社区之间共享信息必须经过转换过程,而关键在于从一个模式转换到另一个模式会使得源模式中的信息不再存在,而是被新目标模式的新信息所取代。语义 Web 的描述当使用目标知识域来描述源知识域中的概念时,完全是一个加性的过程,不会产生转换过程的信息损失。
尽管 RDF 提供了一种信息建模的方式,但它并没有提供描述信息的含义(即语义)的方法。为了能够向 RDF 加入恰当的语义,我们需要以某种方式来定义一个预定义的词汇集,同时确定描述信息的语义。
- RDFS 为 RDF 提供了一个特定的词汇表,该词汇表可以用于定义类和属性的分类层次,以及对属性定义域、值域等的简单描述;
- OWL Web 本体语言为定义本体提供了一种富表达力的语言,能够捕捉领域知识的语义。OWL 2 扩展了原有的 OWL 词汇表并重用了同一个名称空间。
| 名称空间 | 前缀 |
|---|---|
http://www.w3.org/1999/02/22-rdf-syntax-ns# | rdf |
http://www.w3.org/2000/01/rdf-schema# | rdfs |
http://www.w3.org/2001/XMLSchema# | xsd |
http://www.w3.org/2002/07/owl# | owl |
OWL 引入了一些在 RDFS 中没有明确出现的额外词汇和结构假设,因此,不论你在自己系统上使用了什么样的语言元素集合,都应当将自己的知识模型建立在 OWL 基础之上。否则从 RDFS 转到 OWL 是很痛苦的。
# 4.2 两个重要假设:开放世界假设和命名不唯一假设
OWL 本体用于对领域知识进行建模,它是语义 Web 的核心元素。
语义 Web 是为了使万维网变得更容易被计算机理解,其资源本质上是分布式的,因此语义 Web 是分布式的知识模型。为了在分布式知识模型中进行推理,这两个假设就十分重要了。
# 4.2.1 开放世界假设
开放世界假设:如果没有明确地知道一条陈述是否为真,则并不意味着该陈述一定为假。
封闭世界假设:如果不知道一条陈述是否为真,则可以认为这条陈述为假。
举例: 假设在关系型数据库中,沃尔玛商场的客户信息表中没有 Ryan 的购物记录,就意味着 Ryan 不是自己的客户;而在语义 Web 上,如果描述 Ryan 是沃尔玛的客户的陈述不存在,则并不能说明他不是沃尔玛的客户。
在语义 Web 中,对 OWL 语义的正确推理依赖于遵从开放世界假设。
# 4.2.2 命名不唯一假设
命名不唯一假设:除非有明确说明,否则你不能假定使用不同 URI 标识的资源是不同的。
比如同样一个人,可能被他的邮件地址、博客地址等多种信息所制成的 URI 来标识,但这些不同 URI 所指示的其实是同一个人。
这种假设与很多传统系统所使用的假设也是不同的,比如大多数数据库系统中,所有已知信息都被指定了唯一的主键,这个主键可以在整个系统中一致地使用。
# 4.3 本体的构成元素
OWL 本体一般以文档的形式进行存储,由于 OWL 基于 RDF,所以本体和实例之间并没有官方的划分,这种划分是任意的,并不会影响到信息的含义。但为了方便维护,将本体和本体所描述的实例数据分开是常见的做法。
本体中的资源可以分为个体(类的实例)、类或者属性等类型,OWL 2 描述了一系列关于如何在本体中指定资源类型的约束。有关将这些类型应用于 URI 的约束如下所示:
- 对象、数据类型和标注属性必须是不相交的。一个 URI 不能表示多种类型的属性,
- 类和数据类型必须是不相交的。一个 URI 不能既表示一个类又表示一个数据类型属性。
# 4.3.1 本体首部
本体首部是对本体本身的描述。一个本体文档中并非必须包含本体首部,但是包含本体首部是比较好的形式。它可能含有注释信息,如版本和兼容性等信息。这里先不对本体首部作更多介绍。
# 4.3.2 标注
标注是使用标注属性来描述资源的那些陈述。标注属性是语义自由(即没有语义上的含义)的属性。它可以用于描述本体中的任何资源或者公理,包括本体本身。
| 属性 | 用法描述 |
|---|---|
| rdfs:label | 一个名称,或者是对主题资源的简要描述 |
| rdfs:comment | 关于主题资源的注释 |
| owl:versionInfo | 关于主题本体或者资源的版本信息 |
# 4.4.3 类和个体
# 类和个体的概念
同一类事物就是指和它具有共同特征的事物。一个类的成员(或者说实例)被称作个体。一个个体可以属于多个类。
- owl:Class:表示了包含所有 OWL 类的类。OWL 中每个类都必须是 owl:Class 的成员,而且每个类型为 owl:Class 的资源都表示一个类。比如
ex:Human rdf:type owl:Class表示 ex:Human 是一个“人”类。 - rdf:type:对一个资源赋予某个类。比如
ex:Ryan rdf:type owl:Class表示 Ryan 属于人类。
OOP 对比 OWL
很多人会将 OWL 的类和 OOP 中的类进行类似对比。OOP 中的对象特征取决于它的类型,但 OWL 中个体的类型无法指定它的结构。
# rdfs:subClassOf
ex:Human rdf:subClassOf ex:Mammal 陈述了 ex:Human 是 ex:Mammal 的子类,这意味着:
- ex:Human 是 ex:Mammal 的特化;
- ex:Human 的任何一个成员都必须是 ex:Mammal 的一个合法成员,遵守所有 ex:Mammal 的约束;
- ex:Human 的全体成员蕴含了 ex:Mammal 的全体成员;
- ex:Mammal 的属性及约束都被 ex:Human 所继承。
示例:
ex:Mammal a owl:Class .
ex:Canine a owl:Class ;
rdfs:subClassOf ex:Mammal .
ex:Human a owl:Class ;
rdfs:subClassOf ex:Mammal .
ex:Daisy a ex:Caine .
ex:Ryan a ex:Human.
2
3
4
5
6
7
8
9
10
通过将这些关系语义存于知识模型中,可以简化应用程序的开发。这样当新加入其他哺乳动物的类型时,应用程序不需要改动便可以查询出所有的哺乳动物。
区分子类关系和实例关系
subclass-of 关系和 instance-of 容易混淆。在上例中,ex:Human 与 ex:Mammal 是 subclass-of 关系,ex:Ryan 与 ex:Human 是 instance-of 关系。
当设计确定一个资源究竟是实例还是子类的时候应当提出的一个关键问题是:这个资源是类的一个成员还是这个类的成员的一个子集?
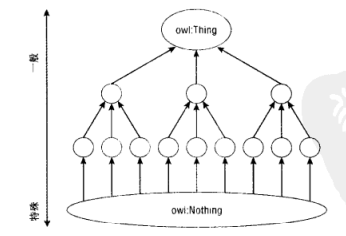
# owl:Thing 和 owl:Nothing
这是 OWL 中的两个基本类:
- owl:Thing 表示所有个体的类,是最一般化的类,所有的 OWL 必定是 owl:Thing 的一个子类;
- owl:Nothing 表示空类,即没有成员的类,是最特殊化的类,是每个 OWL 类的子类。
# 4.4.4 属性
# 定义和使用属性
- owl:ObjectProperty :所有个体之间关系的类
- owl:DatatypeProperty:所有个体和文字值之间关系的类
举例:
ex:name a owl:DatatypeProperty.
ex:breed a owl:ObjectProperty.
ex:Daisy ex:name "Daisy";
ex:breed ex:GoldenRetriever.
2
3
4
5
# 属性的定义域和值域
用来描述属性和类之间或者属性和数据类型之间的定义域关系和值域关系:
- rdfs:domain:指定了哪些类型的个体可以作为一个属性的主语(定义域);
- rdfs:range:指定了哪些类型的个体或文字可以作为一个属性的宾语(值域);
举例:
ex:hasOwner rdfs:range ex:Human
- 陈述了 ex:hasOwner 这个属性的宾语必须是一个人类。
# 4.4.5 描述属性
OWL 提供了多种描述属性(或者说是向属性添加语义)的方式。
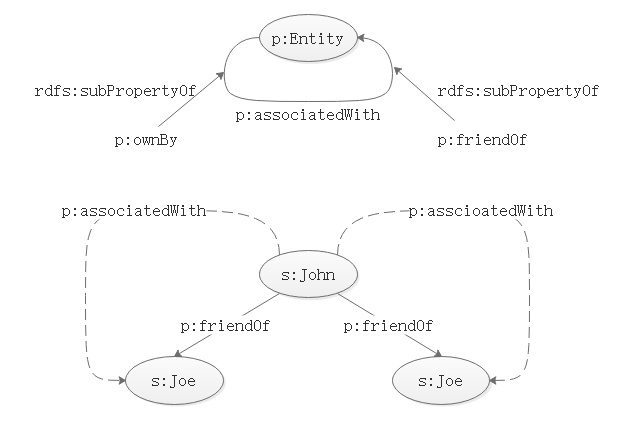
# 1)rdfs:subPropertyOf
ex:p1 rdfs:subPropertyOf ex:p2 声明了 p1 是 p2 的子属性,陈述了以下事实:
- p1 是 p2 的一个特化;
- 任何两个使用 p1 关联起来的资源必然可以使用 p2 关联起来。
# 2)顶属性和底属性
顶属性(Top Property)是最一般属性,底属性(Bottom Property)是最特殊属性,所有其他属性都是由这两个属性派生而来的:
- owl:topObjectProperty 和 owl:topDataProperty
- owl:bottomObjectProperty 和 owl:bottomDataProperty
owl:topObjectProperty 是连接所有可能的个体,owl:bottomObjectProperty 不连接任何个体对。
# 3)逆属性
owl:inverseOf 将一个属性声明为另一个属性的逆属性。
ex:hasChild owl:inverseOf ex:hasParent 隐含了下面的事实:
- ex:hasChild 表示一个关系,该关系恰好为 ex:hasParent 的逆;
- 若存在陈述 (a ex:hasChild b),则必然存在陈述 (b ex:hasParent a)。
# 4)不相交属性
当我们说两个属性 p1 和 p2 是属性不相交的时,就是说不存在以下这样的两条陈述:两条陈述的主语和宾语都相同,却同时以 p1、p2 为谓语。
有两种指定不相交的方式:
✒️ 第一种是使用 owl:propertyDisjointWith,比如 ex:hasMother owl:propertyDisjointWith ex:hasFather;
✒️ 第二种是使用 owl:AllDisjointProperties 和 owl:members 将一个属性集合标识为两两不相交的:
[] rdf:type owl:AllDisjointProperties;
owl:members (
ex:hasMother
ex:hasFather
).
2
3
4
5
- OWL 要求 owl:AllDisjointProperties 的所有实例都是未命名的。
# 5)属性链
占个位 ... 没看懂
# 6)对称属性、自反属性和传递属性
| 属性类 | 定义 |
|---|---|
| owl:SymmetricProperty | (A p B) 蕴含 (B p A) |
| owl:AsymmetricProperty | (A p B) 蕴含一定不存在 (B p A) |
| owl:ReflexiveProperty | 对所有个体 A 都有 (A p A) |
| owl:IrreflexiveProperty | 对所有个体 A 都不存在 (A p A) |
| owl:TransitiveProperty | 如果有 (A p B) 且 (B p C),则蕴含有 (A p C) |
ex:equal rdf:type owl:ReflexiveProperty表示对所有个体 A 都有 (A ex:equal A);ex:hasMother rdf:type owl:IrreflexiveProperty表示对所有个体 A 都不存在 (A ex:hasMother A)。
# 7)函数属性和逆函数属性
- owl:FunctionalProperty 指示一个属性是函数的。比如声明 hasMother 是函数的,则当存在陈述 (A hasMother B) 和 (A hasMother C) 时,可以推理出 B 和 C 是相等的。
- owl:InverseFunctionalProperty 指示一个属性是逆函数的。当一个含有逆函数性质的谓词的陈述中,宾语唯一确定主语。比如声明 hasEmail 是逆函数的,则当存在陈述 (A hasEmail x) 和 (B hasEmail x) 时,可以推理出 A 和 B 是相等的。
# 8)键
一个键描述了这样的属性集合:在以指定类的个体作为主语的陈述中,该集合中属性的值唯一确定该主语、
owl:hasKey 将某个特定的类和一个属性集合联系起来,该属性集合是该类的实例的键。
示例:
ex:Dog owl:hasKey (
ex:name
ex:hasOwner
).
2
3
4
这说明了 ex:hasOwner 和 ex:name 一同唯一地确定了类 ex:Dog 的实例。
键在多个数据源集成时非常重要。不同数据源中的标识符通常全局不唯一,这样一旦多个数据源集成到一起,name本地标识符就会出现重复的情况,这时候可以用生成一个全局范围内唯一的标识符的方法来解决。
# 4.4.6 数据类型
数据类型是用 URI 标识的文字值的值域,预先定义的数据类型大多在 XML Schema Definition(xsd)名称空间中。
常见的有:
- 数值型:xsd:int, xsd:float, xsd:real, xsd:decimal
- 字符串型:xsd:string, xsd:token, xsd:language
- 布尔型:xsd:boolean
- URI:xsd:anyURI
- XML:rdf:XMLLiteral
- 时间型:xsd:dateTime, xsd:dateTimeStamp
可通过 OWL 2 语法文档来获取更多信息。
除了预定义的数据类型之外,OWL 2 还引入了自定义数据类型的功能。
自定义数据类型的方式也先占个位...
# 4.4.7 否定属性断言
否定属性断言用来声明一个个体和另一事物之间不存在某种关系。下例陈述了个体 ex:Daisy 没有所有者 ex:Amber:
[] a owl:NegativePropertyAssertion;
owl:sourceIndividual ex:Daisy;
owl:assertionProperty ex:hasOwner;
owl:targetIndividual ex:Amber.
2
3
4
若想对 data property 进行否定属性断言,只需用 owl:targetValue 代替 owl:targetIndividual。
否定属性断言实际上是类 owl:NegativePropertyAssertion 的实例,根据 OWL规范,这些实例不能具名。
开放世界假设带来的结果是:如果想使某些事物是已知的,就必须将其显式或隐式地表示为解释 OWL 语义所能得到的结果。这时否定属性断言是很有用的。
# 4.4.8 属性约束
属性描述(rdfs:subPropertyOf,owl:inverseOf)和属性类型(对称、自反、传递等)都是对属性的全局描述。有时,在某个特定类的上下文范围之内描述属性同样也很有用,这就是使用属性约束的目的。使用属性约束使您可以规定在将某个属性应用于某个特定类的实例时应该如何使用该属性。属性约束描述了那些满足指定属性条件个体的类。这些约束使用 owl:Restriction 构造来声明,而且约束涉及到的属性都使用属性 owl:onProperty 来标识。
在将约束应用于特定类时,可以通过说明某个特定类声明为该约束的子类(rdfs:subClassOf)或者等价类(owl:equivalentClass)来实现:
- 当使用 subclass-of 关系将类和约束关联起来时,约束规定了类的全体成员所必须满足的条件,即类的所有成员都必须满足约束所规定的条件。
- 当使用 equivalentClass 关系将一个类和一个约束关联起来时,约束规定了将一个个体声明为该类的成员所必须满足的充分必要条件。也就是说,该类的成员必须满足该约束条件,并且所有满足该约束条件的个体必然是该类的成员。
一个类中可以包含多个约束。当出现这种情况时,每个约束都可以以独立于其他约束的方式进行应用,从而创建一个对类的全体成员来说均充分且必要的条件集合。
目前存在两种类型的属性约束:取值和基数。此外,OWL 2 中还引入了受限基数约束,它将基数和取值约束组合到了一起。
# 1)值约束
OWL 提供了三种值约束来指定一个属性的值域:
| 约束 | 解释 |
|---|---|
| owl:allValuesFrom | 对于所有实例,如果它们都具有这种属性,则该属性必须具有指定的值域 |
| owl:someValuesFrom | 对于所有实例,必须至少有一个具有指定值域的属性 |
| owl:hasValue | 对于所有实例,必须有一个具有指定值的属性 |
# 示例 1:【owl:allValuesFrom】
ex:Canine rdfs:subClassOf [
rdf:type owl:Restriction;
owl:onProperty ex:registerdName;
owl:allValuesFrom xsd:string
].
2
3
4
5
- 约束当属性 ex:registerdName 用于类 ex:Canine 的实例时,其值域必须为 xsd:string,否则该个体不合法。
# 示例 2:【owl:someValuesFrom】
ex:Canine owl:equivalentClass [
rdf:type owl:Restriction;
owl:onProperty ex:breed;
owl:someValuesFrom ex:Breed
].
2
3
4
5
- 使用等价类约束,来声明 ex:Canine 的每一个实例都必须至少有一个 ex:breed 属性,且该属性的取值为类 ex:Breed 的实例,而且任何满足这些条件的个体都必然是类 owl:Canine 的一个实例。
- 一定要注意这与说明 ex:breed 的值域是 ex:Breed 是不同的。
- 即使 ex:Canine 有一个 ex:breed 属性指向 ex:Human 的实例也是可以的,因为只要至少有一个符合条件的即可;甚至没有这样的属性也不意味着不合法,因为既然开放世界假设声明了满足该约束条件的属性必然存在,我们就不用担心这个属性到底是什么。
注意:这个例子和后面的一些例子都是使用Turtle的 bnode 语法(使用方括号) 来将约束创建为匿名资源的。OWL 规范要求约束不可以是具名的,而且必须使用匿名资源来定义。这是一个合理的条件,因为在类的上下文中定义的约束仅仅和类的上下文相关,根本不会被引用。
# 示例 3:【owl:hasValue】
ex:PetsOfRyan rdf:type owl:Class;
rdfs:subClassOf ex:Mammal;
rdfs:subClassOf [
rdf:type owl:Restriction;
owl:onProperty ex:hasOwner;
owl:hasValue ex:Ryan
].
2
3
4
5
6
7
- 我们创建了一个新类 ex:PetsOfRyan,要成为该类的成员必须满足两个条件:① 该类的所有成员都必须是哺乳动物,② 所有成员都必须归 ex:Ryan 所有(own)。这个 RDF 代码便是定义了这个类,定义的第一部分说明它是 ex:Mammal 的子类,第二部分含有一个值约束,该约束声明所有 ex:PetsOfRyan 的实例都必须有一个 ex:hasOwner 的属性,且该属性的取值是 ex:Ryan。
# 示例 4:【自约束】
自约束仅仅有一个参数,即应用了该约束的属性,而且这种约束通常用于表示这样的类:所有通过该属性和自身相关的实例所组成的类。
# cleans is an object property
ex:cleans rdf:type owl:ObjectProperty.
#Feline is a subclass of Mammal and Mini is a Feline who cleans herself
ex:Feline rdf:type owl:Class;
rdfs:subClassof ex:Mammal.
ex:Mini rdf:type ex:Feline;
ex:cleans ex:Mini.
# Self cleaners are all individuals who clean themselves
ex:SelfCleaner rdf:type owl:Class;
owl:equivalentclass [
rdf:type owl:SelfRestriction;
owl:onProperty ex:cleans
].
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 上面的例子中含有一个 ex:SelfCleaner 类,它用于定义所有能够清洗自身的个体的集合。在该例子中,Mini 是ex:Feline 类的成员之一,而且 Mini 能够把自己清洗干净。这就意味着Mini是类 ex:SelfCleaner 的一个成员。
# 2)基数约束
占坑 ...
# 4.4.9 枚举类的全体成员
OWL 允许你通过显式地定义枚举类的实例来定义类。在枚举时没有给出的个体不能作为该类的成员。
示例:
ex:Daisy rdf:type ex:Dog.
ex:Cubby rdf:type ex:Dog.
ex:Amber rdf:type ex:Dog.
ex:FriendsOfDaisy rdf:type owl:Class;
owl:oneOf (
ex:Cubby
ex:Amber
).
2
3
4
5
6
7
8
9
- 表示
ex:FriendsOfDaisy这个类的实例只能是ex"Cubby或者ex:Amber。
# 4.4.10 集合运算符
集合运算符可以通过用其他类的全体成员来描述某个类的全体成员。
| 集合运算 | 解释 |
|---|---|
| owl:intersectionOf | 运算结果取所有同时为类 A、B 和 C 的实例的个体 |
| owl:unionOf | 运算结果取所有至少为类 A、B 和 C 其中之一的实例的个体 |
| owl:complementOf | 运算结果取所有不为类 A 的实例的个体 |
示例 1:用 owl:intersectionOf 定义 ex:PetsOfRyan —— 所有既是 ex:Mammal 的成员又是由 ex:Ryan 的 ex:hasOwner 属性描述的事物必然是 ex:PetsOfRyan 的一个成员:
ex:PetsOfRyan rdf:type owl:Class;
owl:intersectionOf (
ex:Mammal
[
rdf:type owl:Restriction;
owl:onProperty ex:hasOwner;
owl:hasValue ex:Ryan
]
).
2
3
4
5
6
7
8
9
示例 2:用 owl:unionOf 定义 ex:FriendsOfRyan —— 这个类的全体成员组成包括这些: ① 一个枚举成员仅有 Daisy 的类 ② 类 ex:FriendsOfDaisy ③ 描述了所有与 ex:Ryan 有 ex:isFriendsWith 关系的个体的约束
ex:FriendsOfRyan rdf:type owl:Class;
owl:unionOf (
[
rdf:type owl:Class;
owl:oneOf (
ex:Daisy
)
]
ex:FriendsOfDaisy
[
rdf:type owl:Restriction;
owl:onProperty ex:isFriendsWith;
owl:hasValue ex:Ryan
]
).
2
3
4
5
6
7
8
9
10
11
12
13
14
15
示例 3:使用 owl:complementOf 定义 ex:EnemiesOfRyan —— 其全体成员是 ex:FriendsOfRyan 的全体成员的补集:
ex:EnemiesOfRyan rdf:type owl:Class;
owl:complementOf ex:FriendsOfRyan.
2
# 4.4.11 不相交类
当两个类是不相交类时,它们的任一实例都不可能成为对方的实例。声明不相交类的方式:
方法一:用 owl:disjointWith 属性将两个类关联起来:
ex:Canine owl:disjointWith ex:Human
- 声明了类 ex:Canine 的任何实例都不能成为 ex:Human 的实例
方法二:构造 owl:AllDisjointClasses 和 owl:members 将一个类集合定义为两两不相交的:
ex:Animal rdf:type owl:Class.
ex:Bird rdf:type owl:Class.
rdfs:subclassOf ex:Animal.
ex:Lizard rdf:type owl:Class.
rdfs:subclassOf ex:Animal.
ex:Feline rdf:type owl:Class.
rdfs:subclassOf ex:Animal.
_: rdf:type owl:AllDisjointClasses;
owl:members (
ex:Bird
ex:Lizard
ex:Canine
).
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
方法三:使用 owl:disjointUnionOf 表达不相交并集的概念:
ex:Animal owl:disjointUnionOf (
ex:Bird
ex:Lizard
ex:Feline
ex:Canine
).
2
3
4
5
6
- ex:Animal 是由不相交的下面四个类组成的一个新类。
区分好不相交属性和不相交类。
# 4.4.12 OWL 中的等价
- owl:sameAs 声明两个拥有不同 URI 的个体是相同的。
- owl:differentFrom 声明两个 URI 指代的是不同个体。这个属性很重要,因为在遵从命名不唯一假设的环境下,不能直接认为两个不同的 URI 标识的资源是不同的。
- owl:AllDifferent 和 owl:distinctMembers 可以构造一个包含两两互不相同的个体的集合从而减少使用 differentFrom 的陈述的数目。
[] rdf:type owl:AllDifferent;
owl:distinctMembers (
ex:Daisy
ex:Cubby
ex:Amber
).
2
3
4
5
6
- owl:equivalentClass 声明两个类是等价的。类等价之后,所有类约束和类扩展都可以共享。
- owl:equivalentProperty 声明两个属性是等价的。属性等价之后,它们的属性描述就组合到一起了。