 RESCAL and Its Extensions
RESCAL and Its Extensions
在知识表示学习的 model 中,有一类是语义匹配模型(Semantic Matching Models),这种模型的含义借助文献 [1] 的解释如下:
Semantic matching models exploit similarity-based scoring functions. They measure plausibility of facts by matching latent semantics of entities and relations embodied in their vector space representations.
本文主要介绍其中的 RESCAL 及其各类扩展模型。
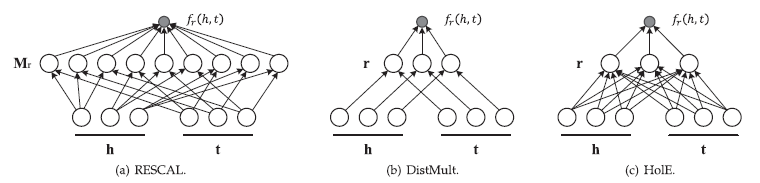
# 1. RESCAL
矩阵分解是得到低维向量表示的重要途径,因此,有研究者提出采用矩阵分解进行知识表示学习,这方面的代表方法是 RESCAL 模型[2],同时它也是一种双线性模型,发表的 paper 也是双线性模型的开山之作。
# 1.1 Model
在该模型中,知识库三元组构成了一个大的 tensor
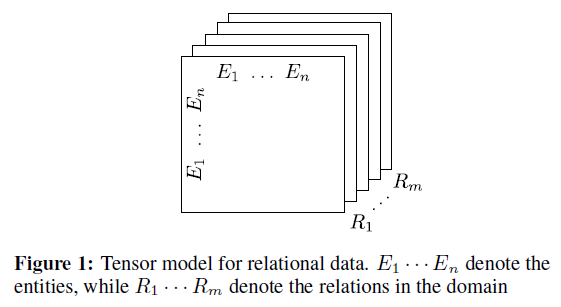
- 共有 n 个 entity,m 个 relation,
RESCAL 将每个 entity 表示为一个 vector,将每个 relation 表示为一个 matrix,对每个 slice
分解后的 A 是一个
特别要提的是
是非对称矩阵,这样可以建模非对称关系,在同一个实体作为头实体或尾实体时会得到不同的 latent component representation。
具体计算
# 1.2 score function
其实,纵观 RESCAL,它的 score function 就是下面这个双线性函数:
This score captures pairwise interactions between all the components of
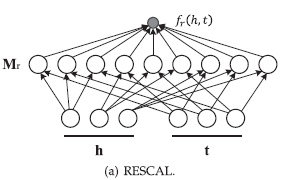
由上图可以看到,RESCAL 计算的 score 捕捉了成对的
# 1.3 代码实现
RESCAL 实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class RESCAL(nn.Module):
def __init__(self, ent_num, rel_num, device, dim=100, norm=1, alpha=0.001):
super(RESCAL, self).__init__()
self.ent_num = ent_num
self.rel_num = rel_num
self.device = device
self.dim = dim
self.norm = norm # 使用L1范数还是L2范数
self.alpha = alpha
# 初始化实体向量
self.ent_embeddings = nn.Embedding(self.ent_num, self.dim)
torch.nn.init.xavier_uniform_(self.ent_embeddings.weight.data)
self.ent_embeddings.weight.data = F.normalize(self.ent_embeddings.weight.data, 2, 1)
# 初始化关系矩阵
self.rel_embeddings = nn.Embedding(self.rel_num, self.dim * self.dim)
torch.nn.init.xavier_uniform_(self.rel_embeddings.weight.data)
self.rel_embeddings.weight.data = F.normalize(self.rel_embeddings.weight.data, 2, 1)
# 损失函数
self.criterion = nn.MSELoss()
def get_ent_resps(self, ent_idx): #[batch]
return self.ent_embeddings(ent_idx) # [batch, emb]
# 越大越好,正例接近1,负例接近0
def scoring(self, h_idx, r_idx, t_idx):
h_embs = self.ent_embeddings(h_idx) # [batch, emb]
t_embs = self.ent_embeddings(t_idx) # [batch, emb]
r_mats = self.rel_embeddings(r_idx) # [batch, emb * emb]
norms = (torch.mean(h_embs ** 2) + torch.mean(t_embs ** 2) + torch.mean(r_mats ** 2)) / 3
r_mats = r_mats.view(-1, self.dim, self.dim)
t_embs = t_embs.view(-1, self.dim, 1)
tr_embs = torch.matmul(r_mats, t_embs)
tr_embs = tr_embs.view(-1, self.dim)
return torch.sum(h_embs * tr_embs, -1), norms
def forward(self, h_idx, r_idx, t_idx, labels):
scores, norms = self.scoring(h_idx, r_idx, t_idx)
tmp_loss = self.criterion(scores, labels.float())
tmp_loss += self.alpha * norms
return tmp_loss, scores
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
# 2. DistMult
本文提出了 neural-embedding 的通用框架,并把 NTN、TransE 等模型套在框架里进行对比;提出了将关系矩阵限制为对角矩阵的 DistMult;并用 embedding-based 方法挖掘逻辑规则。
# 2.1 Model
DistMult[3] 通过限制双线性矩阵为对角阵来简化了 RESCAL。对每一个 relation
计算 score 的方式如下图:
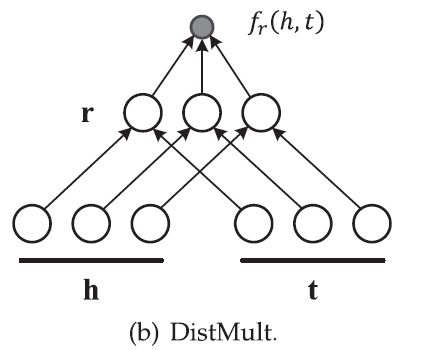
由上图可以看到,DistMult 计算的 score 只捕捉了成对的
paper 还给出了这个模型在规则抽取上的实验,可以参考学习。
# 2.2 代码实现
pykg2vec 上给出了 DistMult 的实现:
DistMult 实现
class DistMult(PointwiseModel):
"""
`EMBEDDING ENTITIES AND RELATIONS FOR LEARNING AND INFERENCE IN KNOWLEDGE BASES`_ (DistMult) is a simpler model comparing with RESCAL in that it simplifies
the weight matrix used in RESCAL to a diagonal matrix. The scoring
function used DistMult can capture the pairwise interactions between
the head and the tail entities. However, DistMult has limitation on modeling asymmetric relations.
Args:
config (object): Model configuration parameters.
.. _EMBEDDING ENTITIES AND RELATIONS FOR LEARNING AND INFERENCE IN KNOWLEDGE BASES:
https://arxiv.org/pdf/1412.6575.pdf
"""
def __init__(self, **kwargs):
super(DistMult, self).__init__(self.__class__.__name__.lower())
param_list = ["tot_entity", "tot_relation", "hidden_size", "lmbda"]
param_dict = self.load_params(param_list, kwargs)
self.__dict__.update(param_dict)
num_total_ent = self.tot_entity
num_total_rel = self.tot_relation
k = self.hidden_size
self.ent_embeddings = NamedEmbedding("ent_embedding", num_total_ent, k)
self.rel_embeddings = NamedEmbedding("rel_embedding", num_total_rel, k)
nn.init.xavier_uniform_(self.ent_embeddings.weight)
nn.init.xavier_uniform_(self.rel_embeddings.weight)
self.parameter_list = [
self.ent_embeddings,
self.rel_embeddings,
]
self.loss = Criterion.pointwise_logistic
def embed(self, h, r, t):
"""Function to get the embedding value.
Args:
h (Tensor): Head entities ids.
r (Tensor): Relation ids of the triple.
t (Tensor): Tail entity ids of the triple.
Returns:
Tensors: Returns head, relation and tail embedding Tensors.
"""
h_emb = self.ent_embeddings(h)
r_emb = self.rel_embeddings(r)
t_emb = self.ent_embeddings(t)
return h_emb, r_emb, t_emb
def forward(self, h, r, t):
h_e, r_e, t_e = self.embed(h, r, t)
return -torch.sum(h_e*r_e*t_e, -1)
def get_reg(self, h, r, t, reg_type="F2"):
h_e, r_e, t_e = self.embed(h, r, t)
if reg_type.lower() == 'f2':
regul_term = torch.mean(torch.sum(h_e ** 2, -1) + torch.sum(r_e ** 2, -1) + torch.sum(t_e ** 2, -1))
elif reg_type.lower() == 'n3':
regul_term = torch.mean(torch.sum(h_e ** 3, -1) + torch.sum(r_e ** 3, -1) + torch.sum(t_e ** 3, -1))
else:
raise NotImplementedError('Unknown regularizer type: %s' % reg_type)
return self.lmbda*regul_term
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
# 3. HolE
# 3.1 compositional vector space models
论文首先提出了 compositional vector space models,它提供了一种优雅的方式来学习 KG 中 relation 的 characteristic function,并可以将这个学习任务转化为 supervised representation learning 问题。这种模型的形式如下:
假设
对于关系数据,最小化 logistic 损失具有额外的优势,它可以帮助为复杂的关系模式找到低维的嵌入。
由于 KG 只存储正确三元组,这种情况我们可以使用 pairwise ranking loss 来 rank the probability of existing triples higher than the probability of non-existing ones:
RESCAL 套在上面的模型中就是
# 3.2 Model
HolE 就是将上面说的 compositional vector space models 的
取 circular correlation 的情况。在HOLE中,不只是存储关联,而是学习能最好地解释所观察到数据的嵌入。
HolE[4] combines the expressive power of RESCAL with the efficiency and simplicity of DistMult.
HolE 将每个 entity 和 relation 都表示为一个在
这个计算得到的 compositional vector 然后去与 relation representation 进行匹配得到 fact 的 score:
为了学习到 entity 和 relation 的 representation,我们可以使用 SGD 来优化:
以优化
其他的公式可以参考原论文。
# 3.3 Circular Correlation
Circular Correlation 可以看成是 tensor product 的一种 compression,是一种
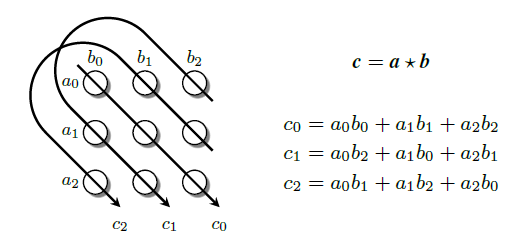
在具体实现时,circular correlation 可以通过如下的方式进行计算:
Circular correlation 在成对的 h 和 t 的 interaction 中做了 compression,它只要求
# 3.4 代码实现
HolE 实现
class HoLE(PairwiseModel):
"""
`Holographic Embeddings of Knowledge Graphs`_. (HoLE) employs the circular correlation to create composition correlations. It
is able to represent and capture the interactions betweek entities and relations
while being efficient to compute, easier to train and scalable to large dataset.
Args:
config (object): Model configuration parameters.
.. _Holographic Embeddings of Knowledge Graphs:
https://arxiv.org/pdf/1510.04935.pdf
"""
def __init__(self, **kwargs):
super(HoLE, self).__init__(self.__class__.__name__.lower())
param_list = ["tot_entity", "tot_relation", "hidden_size", "cmax", "cmin"]
param_dict = self.load_params(param_list, kwargs)
self.__dict__.update(param_dict)
self.ent_embeddings = NamedEmbedding("ent_embedding", self.tot_entity, self.hidden_size)
self.rel_embeddings = NamedEmbedding("rel_embedding", self.tot_relation, self.hidden_size)
nn.init.xavier_uniform_(self.ent_embeddings.weight)
nn.init.xavier_uniform_(self.rel_embeddings.weight)
self.parameter_list = [
self.ent_embeddings,
self.rel_embeddings,
]
self.loss = Criterion.pairwise_hinge
def forward(self, h, r, t):
h_e, r_e, t_e = self.embed(h, r, t)
r_e = F.normalize(r_e, p=2, dim=-1)
h_e = torch.stack((h_e, torch.zeros_like(h_e)), -1)
t_e = torch.stack((t_e, torch.zeros_like(t_e)), -1)
e, _ = torch.unbind(torch.ifft(torch.conj(torch.fft(h_e, 1)) * torch.fft(t_e, 1), 1), -1)
return -F.sigmoid(torch.sum(r_e * e, 1))
def embed(self, h, r, t):
"""
Function to get the embedding value.
Args:
h (Tensor): Head entities ids.
r (Tensor): Relation ids of the triple.
t (Tensor): Tail entity ids of the triple.
Returns:
tuple: Returns a 3-tuple of head, relation and tail embedding tensors.
"""
emb_h = self.ent_embeddings(h)
emb_r = self.rel_embeddings(r)
emb_t = self.ent_embeddings(t)
return emb_h, emb_r, emb_t
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
参考文献
[1] Wang, Q., Mao, Z., Wang, B. & Guo, L. Knowledge Graph Embedding: A Survey of Approaches and Applications. IEEE Transactions on Knowledge and Data Engineering 29, 2724–2743 (2017).
[2] Nickel, M., Tresp, V. & Kriegel, H.-P. A Three-Way Model for Collective Learning on Multi-Relational Data. in 809–816 (2011).
[3] Yang, B., Yih, W., He, X., Gao, J. & Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. Preprint at https://doi.org/10.48550/arXiv.1412.6575 (2015).
[4] Nickel, M., Rosasco, L. & Poggio, T. Holographic Embeddings of Knowledge Graphs. Preprint at https://doi.org/10.48550/arXiv.1510.04935 (2015).